編集履歴
- '20/01/28: 3rd solutionを追加
これはなに?
- Kaggleで10/24-1/23に開催されたData Science Bowl 2019コンペの上位解法まとめです。
- 1/27時点で公開されている10位以内の解法をまとめてみました。
- Shake-up/downの激しいコンペでしたが、上位入賞されている方の解法には学ぶところが多く、上位に入るべくして入った方が多い印象でした。
- 流し読みしてまとめたので、間違っているところとかお気づきの点あればご指摘ください。
- 金メダル圏内のものがあと4つぐらい公開されていたので後で足そうと思います。
1st
Stats
private 0.568 / public 0.563
要約
- LightGBMのシングルモデル(!)
- Foldごとにシードを変えた5Fold
詳細
Validation
- LBが不安定なので見なかった
- 以下2つのValidationSetを利用した
- GroupK CV (installation_id / 5x5Fold)
- QWKが不安定だったので加重平均RMSEを採用した
- weight: the weight is the sample prob for each sample (We use full data, for the test part, we calculate the expectation of the sample prob as weight). (Assessmentが何回あったか、の逆数を取っている?)
- Nested CV
- 上記CVは直感に反する結果が出ることがあった
- そのため、手元でTrainを分割してチェックに使った
- 疑似train: 全ログを使った1400ユーザー
- 疑似test: ログを一部打ち切った2200ユーザー
- これを50-100回行って、(testの評価の?)平均をValidationとして確認した
- GroupK CV (installation_id / 5x5Fold)
Feature Engineering
量
- 2万個ぐらい特徴量を作って、null importanceで500個まで削った
内容
- 同じAssessmentか、類似したゲームに関連する特徴量が非常に大切だった。
(基本的にゲーム内の順序をもとに、ゲームが
どのAssessmentと似ているかをマッピングした。) - mean/sum/last/std/max/slope を true attempt, correct true, correct feedback に対して算出した。
ログデータを以下のように分割して特徴量を作った
- 全履歴
- 過去5/12/48時間
- 前回のAssessmentから現在まで
Eventインターバル特徴量を作り、mean/lastをevent_idやevent_codeでグルーピングして算出した。
- いくつかのEventインターバル特徴量はかなり効いていた
- Videoスキップ特徴量を作った
clip eventインターバル / clip時間で算出- clip時間はオーガナイザーが出してくれてたもの
event_id / event code組み合わせに対する特徴量event_code2030_misses_mean
Feature Selection
- 重複した特徴量の削除
- Adversarial AUC が0.5になるように削除
- null importance (TOP500に)
Model
- testでaccuracy_groupがわかるものはtrainに使った
- trainにはRMSEを使い、validationには加重平均RMSEを使った
Ensemble
- 行っていない
- 0.8xLightGBM+0.2xCatBoostのアンサンブルモデルはprivate0.570だったが 最終サブには使っていない(手元のCVが悪かったから)
2nd
Stats
private 0.563 / public 0.563
要約
- LightGBM / CatBoost / NN のアンサンブル
- 基本的な特徴量に加え、経過によって減衰させた特徴量やword2vecを活用。
- 集約する前のログの各行を予測する特徴量も活用。
詳細
Validation
- 1ユーザーあたり1サンプルになるようにリサンプル
- StratifiedGroupKFold, 5-fold
Feature Engineering
基本的な特徴量
- session, world, types, title, event_id, event_code をワールド別や全体でカウント
- sessionごとに半減して減衰させてカウント
- 経過日数で減衰させてカウント
- num_correct, num_incorrect, accuracy, accuracy_groupに対して大量の統計値を算出
- 前回のAssessmentからの経過時間
Word2Vec
- Assessmentまでのタイトルの履歴を文章とみなす → word2vecでタイトルをベクトル化 → 集計
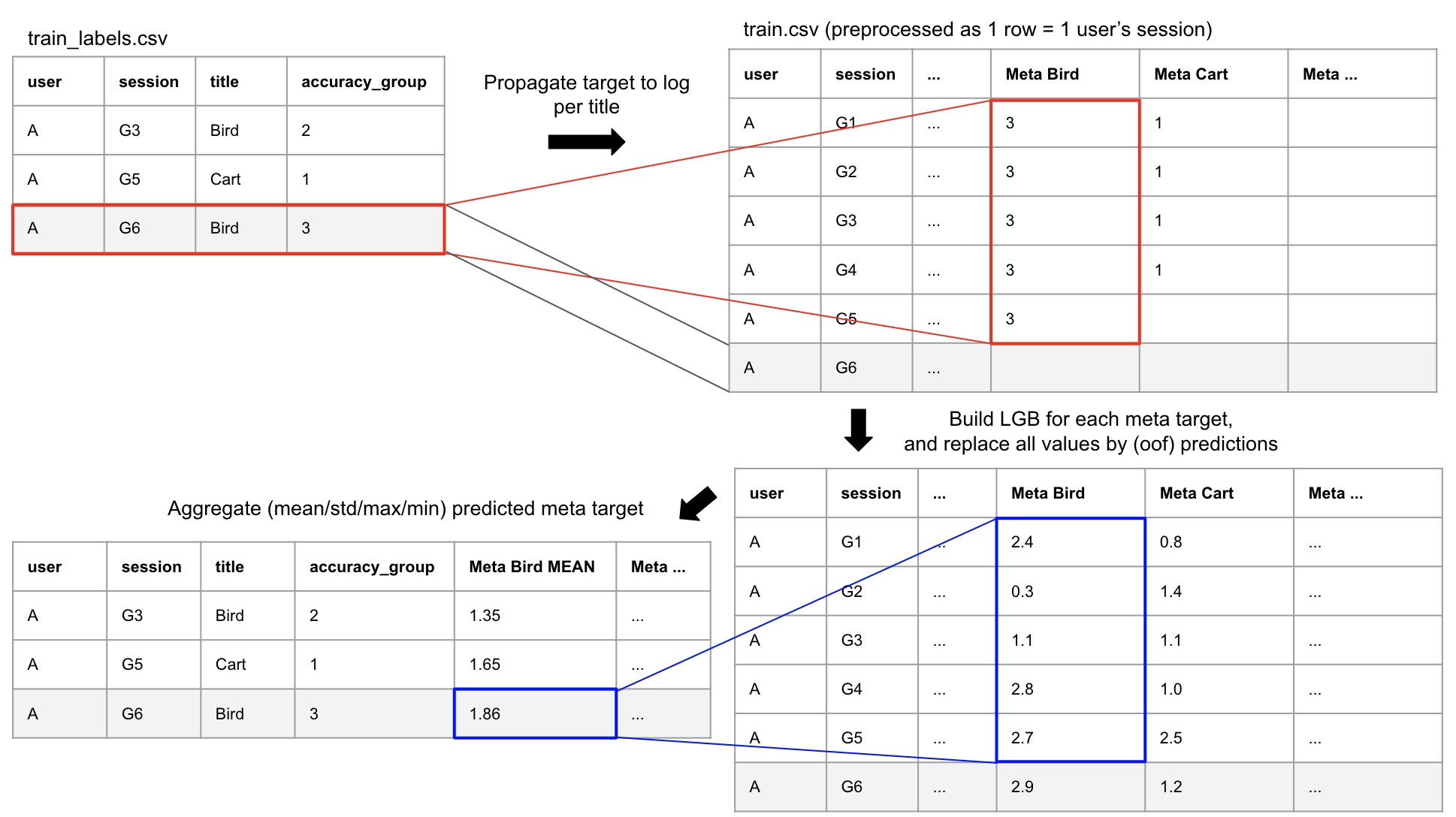
Meta Features
- ログデータの各行にAssessmentの評価を付与→予測→集約
 出典
出典
Feature Selection
- 重複した特徴量の削除
- 相関が高い特徴量の削除
- null importance (TOP300)
Model / Ensemble
- アンサンブル: 0.5 x LightGBM + 0.2 x CatBoost + 0.3 x NN
- 各モデルは 5seed averaging
3rd
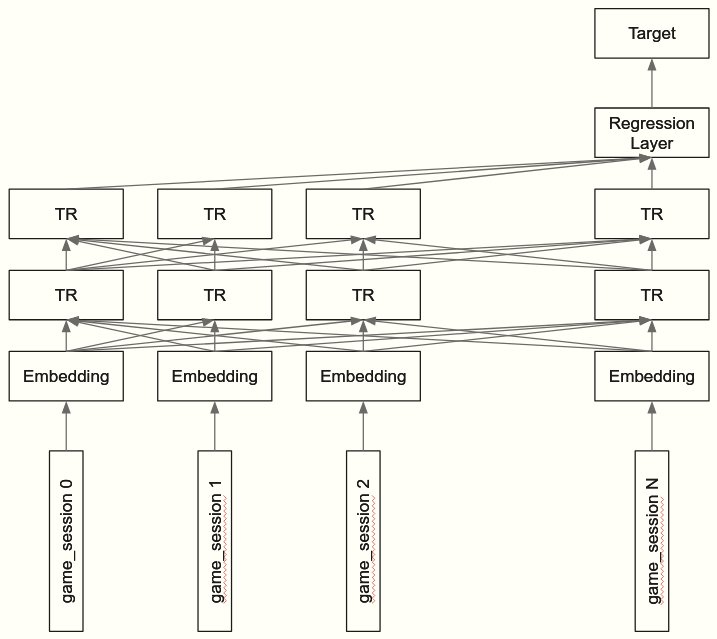
- 5-fold TRANSFORMER Model(Single Model)
- private LB 0.562 / public LB 0.576
- 韓国の旧正月で忙しいからまた書くわ、とのことです。
('20/01/28追記: 書いてくださったので追記しました)
3rd solution - single TRANSFORMER model
前置き(意訳)
- DNNで問題を解くのが好きだからなるべく多くの問題をDNNで解いている
- データそのものの理解よりはデータの構造に着目し、なるべく情報の欠損がないようにモデルに入力するよう心がけている。
- 言い換えると、特徴量エンジニアリングよりもデータにより良くフィットするNNのネットワークデザインの発見により注力している。
詳細
注目すべき点
- 位置関係の情報はCVを下げたので、BERT/ALBERT/GPT2といったposition-embeddingを使うものは精度が良くなかった。
- そのため、position-embeddingを使わないTransformerモデルを組んだ
Pre-processing
- game_sessionごとにevent_code/event_id/accuracy/max_roundなどのカウントを集計
- game_sessionを単語に見立ててシーケンスとしてモデルに入力する
Model
- 100 sessionを入れた (短いシーケンスはPADで埋めた)
- embeddingの作り方
- Categorical変数: ['title', 'type', 'world']
- 個別にembed→concat→nn.linearで次元削減
- 連続値の変数: ['event_count', 'game_time', 'max_game_time'] (+accuracy/max_round?)
- np.log1pで正規化→nn.linearで直接embed
- Categorical変数: ['title', 'type', 'world']
- params
- optimizer: AdamW
- schedular: WarmupLinearSchedule
- learning_rate: 1e-04
- dropout: 0.2
- number of layers : 2
- embedding_size: 100
- hidden_size: 500

{kind=link}
{kind=link}
Loss function
- accuracy_groupの定義を以下のように再構成した
new_accuracy_group = 3 * num_correct - num_incorrect (num_incorrect: contrained not to exceed 2) (new_accuracy_group >= 0 の制約も入れてる、はず…?)
- [num_correct, num_incorrect] をターゲットとして、mseをmodified_lossとして扱った。
- accuracy_group もtargetに入れて、最終的に以下のようにしてaccuracy_groupの予測とした
new_accuracy_group = 3 * num_correct_pred - num_incorrect_pred final_accuracy_group = (accuracy_group_pred + new_accuracy_group) / 2
Data Augumentation
- 多く(30以上)のゲームセッションがあるユーザーのセッションをランダム除去した
- Train: 古い順に最大50%をランダム除去
- Test: 同60%をランダム除去
Data Augumentation (pre-train用)
- Game typeのセッションからpre-train用の学習データを生成した
- Gameセッションのcorrectからnum_correct/num_incorrect/accuraby_group(のようなもの)を作ってデータを増幅
- 41,194のデータをtrainに加えることが出来た
- 学習方法
- pre-train: original label + 上記の学習データ
- fine-tuning: original labelのみ
4th
Stats
- private 0.561 / public 0.572 (NNのブレンド)
- private 0.560 / public 0.566 (3階建てStacking)
詳細
Validation
色々頑張ったけどうまく行かなかったからごく普通にやった
(installation_idのGroupKですらなかった)
Feature Engineering
- testでaccuracy_groupがわかるものはtrainに使った
- 決定木系にいれると悪化したので使わなかった
- いくつかのClipやタイトルは非常に重要だった
- EventシーケンスのTfIDFを活用
- 各event_idをtitle + event_code + correct_flag + incorrect_flagに変換 → ユーザーのシーケンスを文章とみなす → TfIDF
- Assessment, タイトル, Assessmentの評価, だけにTfIDF使っても効かなかった
- NNにはNNに適した特徴量を出すように心がけた
- タイトルのembedding (7次元)
- タイトルの正解/不正解数およびその比率
- タイトル開始時間からの経過時間(秒)
- 以前のタイトルの正解/不正解数およびその比率
Model / Ensemble
3階建てStacking (NNブレンドよりも弱かった)
- RNNx3, lgbm, catboost
- ダブルクロスバリデーション (5x5)
- MLP(x100 starts averaging), Lightgbm(x100 seed averaging)
- Ridge
- RNNx3, lgbm, catboost
全てのモデルは回帰で学習させた
- code(NN)
7th
Stats
Private 0.559 / Public 0.559 / CV 0.575
要約
- 特徴量エンジニアリングが肝だった。最後は51特徴量を使った。(150個から削った)
0.3 LGB, 0.3 CATB, 0.4 NNのアンサンブルだった- 20Foldのバギングを全モデルに適用し、NNはさらに3seed averagingを行った
- testでaccuracy_groupがわかるものはtrainに使った
- Validationではテストセットの構造を考慮して、各ユーザーから1Assessmentをランダム抽出した。
8th
Stats
Private 0.558 / Public 0.556
要約
- シンプルな3層MLP(256x256x256)
詳細
Validation
- 5 GroupKFold
- inversely weighted oof qwk をウォッチしていた
- discussionに書いた、らしい、
Feature Engineering
- Preprocess
- Log transform → std transform
- fillna with zeros
- NaNだったことを示す新たな特徴量を追加
- 2サブのうち片方はtestでaccuracy_groupがわかるものをtrainに使った
- 使ったサブ: 0.559 private
- 使わなかったサブ: 0.552 private
- 主要な特徴量 (8thより上位にあったものは省く)
- titleのdurationが16分より長いものはクリップし、フラグを立てた。
- 子どもたちが16分連続で同じタイトルをやってるのは考えづらい
- titleの平均ミスをround_durationで割ったもの
- リピート特徴量
- titleのdurationが16分より長いものはクリップし、フラグを立てた。
Feature Selection
- null importance
- 1100特徴量を作って216個を選んだ
Model
- シンプルな3層MLP(256x256x256) x 9models(seed違いだけ?)
- 各層でBatch Normalization / Dropout 0.3
- 3xleaky Relu + 1linear
- ecpochは63/65/68と僅かに変えた
- Optimizer: Adam / BatchSize: 128
- learning_rate: 0.0003 w/cyclic decay
- cyclic decay: コードが共有されている
- accuracy_groupに加えて、3 x sqrt(accuracy)も目的関数として利用
- 離散値より多くの情報をモデルが学習できるように
- だが、あまり大きな影響はなかったとのこと
- アンサンブル
- 9models x 2outputs = 18prediction のブレンディング
- code
その他
- thresholdは25回回してCVが一番良かったものを選んだ
- trainのtarget分布に合わせるよりも最適化したほうが良かった
9th
Stats
要約
- ほぼaggregation特徴量で特徴量エンジニアリング
- いくつかの多様なモデルを作ってStacking
- 巨大なランダムサーチによるしきい値探索
詳細
Model
- Stacking が非常に効いた
- LightGBM x 7 + NN x 1 → Ridge
- LightGBM
- gbdt/goss/dart
- targetをいくつか利用した
- accuracy_group
- accuracy
- accuracy_group > 2
- accuracy_group > 1
- accuracy_group > 0
Threshold tuning
- 公開KernelのOptimizedRounderは初期値に依存し、局所最適解に陥る挙動が多かった。
- そのため、truncateしたtrainをランダムサーチするようにした。
10th
詳細
Validation
- StratifiedKFold 10fold
- 各installation_idから1サンプルづつ(?)ランダム抽出
- 各Foldで51validation setsを利用
- 1つはearly_stopingに
- 残り50個でqwkの平均を取ってvalidation score算出する
Feature Engineering
- 3000-5000個ぐらい作って300個を利用した
- magic featureはなかったと思う
- 主要な特徴量 (10thより上位にあったものは省く)
- 正規化したaccuracy系特徴量
- タイトルごとに難易度が違うのでaccuracy系特徴量を正規化したものも利用した
- 例: (Accuracy - Accuracy_mean_per_title) / Feature_std_per_title
- タイトルごとに特徴量を作った
- 例:
target_distances length in Air Show - 多すぎて10タイトル分作って挫折した
- 例:
- 正規化したaccuracy系特徴量
Feature Selection
- LightGBMのfeature_importanceを元に300個を選んだ
- 各Foldで50個のデータセットを作り、5iterationごとにLightGBMのinit_modelパラメーターを使ってデータセットを変えた。(よくわからなかった…)
Model
- LightGBM x 6seed averaging
- feature_fractionは1.0にした
- タイトルごとに平均正答率が違うので全ての木で使うのが良かったのだろう
Threshold
- local CV が最大化するしきい値を固定しこれをprivateでも利用した