遅くないpandasの書き方
これは何?
- この記事は Kaggle Advent Calendar 2021 の7日目の記事です。
- pandasはデータ分析ライブラリとして非常に便利ですが、書き方を間違えると簡単に処理が遅くなってしまうという欠点があります。そこで、この記事では遅くならない書き方をするために気をつけたいポイントをいくつかご紹介したいと思います。
- この Colab Notebookの実行結果をエクスポートした上で、不要な部分を一部削って記事にしています。colab notebook をコピーして実行してもらえれば再現することが可能なはずです。(colabにコメント等をいただいても返すことはできないと思います、すみません。)
前提条件
- この記事ではあくまで「遅くない(なりづらい)書き方を紹介する」ことに努めます。よって、以下のような改善点はあるが一旦考慮の外におくものとして話を進めます。
- 並列化ライブラリ
- numbaでのコンパイル
- (cudfなどでの)GPU活用
- BigQuery利用
- 他言語利用(C++とか)
余談
- pandas高速化でググると並列化ライブラリの紹介が結構出てきます
- 基本的にはこの辺りはあんまり調べる必要はないと思っています
- どのライブラリも微妙にpandasとは互換性がないので、どうせ微妙に互換性がないものを学ぶならcudf一択かなと思います。
- 今はcolabに標準で組み込まれていませんが、そのうち組み込まれるはず… (僕の願望も含む)
目次
データ準備
- まずは例に使うデータの準備を行います
- 別に何のデータでもよかったのですが、こちらの記事で使われているデータを適当に加工して使います。
- データ量が少なかったのでカラム数を20倍、行数を100倍に膨らませています。
import gc import string import random import numpy as np import pandas as pd from tqdm.notebook import tqdm tqdm.pandas() def make_dummy_location_name(num=10): chars = string.digits + string.ascii_lowercase + string.ascii_uppercase return ''.join([random.choice(chars) for i in range(num)]) def make_dummy_data(df, location_name): for i in range(20): df[f'energy_kwh_{i}'] = df[f'energy_kwh'] * random.random() df['location'] = make_dummy_location_name() return df !wget https://raw.githubusercontent.com/realpython/materials/master/pandas-fast-flexible-intuitive/tutorial/demand_profile.csv df_tmp = pd.read_csv('demand_profile.csv') df_dummy = pd.concat([ make_dummy_data(df_tmp.copy(), x) for x in range(100) ]).reset_index(drop=True) df_dummy = df_dummy.sample(frac=1).reset_index(drop=True) df_dummy.to_csv('data.csv') display(df_dummy.info()) display(df_dummy[['date_time', 'location', 'energy_kwh_0', 'energy_kwh_1']].head(3))
| date_time | location | energy_kwh_0 | energy_kwh_1 | |
|---|---|---|---|---|
| 0 | 14/7/13 3:00 | DOymwZfkoV | 0.696740 | 0.419453 |
| 1 | 24/7/13 21:00 | smOT74HjRq | 0.213311 | 0.317483 |
| 2 | 4/6/13 9:00 | nKYmHeR2ov | 0.322995 | 0.413001 |
- join / merge の実演に使う適当なデータも作ります
- location_idのリストとしました
locations = df_dummy['location'].drop_duplicates().values df_locations = pd.DataFrame({ 'location': locations, 'location_id': range(len(locations)) }) df_locations.head(3)
| location | location_id | |
|---|---|---|
| 0 | DOymwZfkoV | 0 |
| 1 | smOT74HjRq | 1 |
| 2 | nKYmHeR2ov | 2 |
データ読み込み
さて、ここから実際に話を進めていこうと思います。 まずはデータを読み込むときに気をつけるポイントです
usecols の利用
- データが大きい、かつ、捨てるカラムが多い時は必ず
usecolsを指定しましょう - 読み込み速度が如実に変わります
usecols = ['date_time', 'energy_kwh_0', 'energy_kwh_1', 'energy_kwh_2', 'location']
%%time # usecolsがないとき df = pd.read_csv('data.csv')
CPU times: user 4.84 s, sys: 126 ms, total: 4.97 s
Wall time: 4.96 s
%%time # usecolsがあるとき df = pd.read_csv('data.csv', usecols=usecols)
CPU times: user 2.86 s, sys: 97.1 ms, total: 2.95 s
Wall time: 2.93 s
型指定
- 余裕がないとき以外は型を指定しましょう
- 集計のキーにするカラムは category 型にしておくと集計が早くなるメリットがあります (後述)
- 読み込み速度には影響しませんが、メモリ使用量に大きく貢献するのでメモリ不足で落ちた、等の不要なエラーを防ぐことでトライアンドエラーの効率も上がると思います。
%%time # 型指定しておくとお行儀が良い # 自分で型を考えるのが面倒な時は次節の reduce_mem_usage を使うのでも良い df = pd.read_csv( 'data.csv', usecols=usecols, dtype={ 'date_time': str, 'energy_kwh_0': float, 'energy_kwh_1': float, 'energy_kwh_2': float, 'location': 'category' } )
CPU times: user 2.79 s, sys: 73.1 ms, total: 2.87 s
Wall time: 2.86 s
cudf
- 数億行単位のファイルならcudfを使うのも良いと思います
- Kaggle Riiidコンペデータ(大体1億行ぐらい)ではpandas読み込みでは1分以上かかっているものがcudf読み込みだと3秒で終わるとの投稿もありました
- 読み込んだ後の処理も一部変わるので注意は必要ですが、莫大なデータを扱うときの選択肢として学習コストに見合うパフォーマンスだと思います。
# import cudf # cdf = cudf.read_csv('data.csv')
iterrows は絶対に使わない (applyも)
数多くの記事(1)(2)で取り上げられていて、ご存知の方にとっては「何をいまさら」と思われることかもしれません。
が、この記事のタイトルからしてこのトピックを取り上げないわけにはいかないので紹介させていただきます。
- 遅くない書き方は色々ありますが…
- とりあえず考えるのが面倒なら「numpy行列にしてからループを回せば及第点」だと覚えておけば良い
- 「
np.whereやnp.vectorizeを使ってループ処理を排除すると速い」というのも併せて覚えておくと、困ったときの手段として使えます。
- ref
iterrowsの遅さを体感しよう
基本的に、iterrows を使わない書き方をするだけで9割の破滅的な遅さを回避できます(断言)
業界の有識者の方もこのようなツイートをされています
pandasで速いコードを書きたかったらiterrowsとapplyとtransformを使うなおじさん「pandasで速いコードを書きたかったらiterrowsとapplyとtransformを使うな」 https://t.co/DLmWsBvAUG
— まますたん (@mamas16k) 2021年11月2日
まずはiterrowsの遅さを体感してみましょう。
(実行する処理は何でもいいので適当に書きました。特に意味はありません。)
# 破滅的に遅い patterns = [] for idx, row in tqdm(df.iterrows(), total=len(df)): if row['energy_kwh_0'] > row['energy_kwh_1']: pattern = 'a' elif row['energy_kwh_0'] > row['energy_kwh_2']: pattern = 'b' else: pattern = 'c' patterns.append(pattern) df['pattern_iterrows'] = patterns
CPU times: user 1min 23s, sys: 661 ms, total: 1min 23s
Wall time: 1min 24s
apply にすると少しはマシなように見えるのですが、後述する「遅くない書き方」と比べると比較にならないくらい遅いです。
%%time def func_1(energy_kwh_0, energy_kwh_1, energy_kwh_2): if energy_kwh_0 > energy_kwh_1: return 'a' elif energy_kwh_0 > energy_kwh_2: return 'b' else: return 'c' df['pattern_iterrows'] = df.progress_apply( lambda x: func_1(x['energy_kwh_0'], x['energy_kwh_1'], x['energy_kwh_2']), axis=1 )
CPU times: user 18 s, sys: 494 ms, total: 18.4 s
Wall time: 18.5 s
脳死で書ける書き方 (numpy配列にする)
- とりあえずこう書いておけば死にはしない、という結論を置いておきます
- このデータ例では
iterrowsを回すより100倍前後、applyするより20倍前後早くなっています iterrowsで for ループ回す書き方と非常に似ているので、覚えるのも簡単かと思います
%%time # とりあえず numpy 行列にしてから回せば早い patterns = [] for idx, (energy_kwh_0, energy_kwh_1, energy_kwh_2) in tqdm(enumerate( zip( df["energy_kwh_0"].values, df["energy_kwh_1"].values, df["energy_kwh_2"].values ) ), total=len(df)): # 後は iterrows のコードをそのまま書けば良い if energy_kwh_0 > energy_kwh_1: pattern = 'a' elif energy_kwh_0 > energy_kwh_2: pattern = 'b' else: pattern = 'c' patterns.append(pattern) df['pattern_by_np_array'] = patterns assert np.array_equal(df['pattern_iterrows'], df['pattern_by_np_array']) # 一応確認 (10msぐらいかかってる)
CPU times: user 1.12 s, sys: 18.9 ms, total: 1.14 s
Wall time: 1.17 s
その他色々な書き方
- 上記の書き方はループを回しているからか、最良のパフォーマンスと比べるとやや劣ってしまいます。
- そこで以下でループを回避する方法が2つ紹介しておきます
- numpyの処理と組み合わせると速いので紹介します
np.where の活用
%%time # 簡単な処理なら np.where などで処理することも考える df['pattern_np_where'] = 'c' df['pattern_np_where'] = np.where(df['energy_kwh_0'] > df['energy_kwh_2'], 'b', df['pattern_np_where']) df['pattern_np_where'] = np.where(df['energy_kwh_0'] > df['energy_kwh_1'], 'a', df['pattern_np_where']) assert np.array_equal(df['pattern_np_where'], df['pattern_by_np_array']) # 一応確認 (10msぐらいかかってる)
CPU times: user 68.2 ms, sys: 0 ns, total: 68.2 ms
Wall time: 66.6 ms
np.vectorize の活用
- np.whereで書くような処理は速いのですが、複雑な処理になると、処理を実現する同等の操作を考えるのにまぁまぁ頭を使う必要があります。
- そこで、考えるのが面倒なら
np.vectorizeというnumpyの関数を使う方法があるのでご紹介します。 - 推論する時間のオーバーヘッドがあるためかやや遅いのですが、それで上記の numpy行列にしてから for ループを回すよりは全然速いです。
%%time def func_1(energy_kwh_0, energy_kwh_1, energy_kwh_2): if energy_kwh_0 > energy_kwh_1: return 'a' elif energy_kwh_0 > energy_kwh_2: return 'b' else: return 'c' df['pattern_np_vectorize'] = np.vectorize(func_1)( df["energy_kwh_0"], df["energy_kwh_1"], df["energy_kwh_2"] ) assert np.array_equal(df['pattern_np_vectorize'], df['pattern_by_np_array']) # 一応確認 (10msぐらいかかってる)
CPU times: user 296 ms, sys: 35 ms, total: 331 ms
Wall time: 333 ms
型指定あれこれ
「iterrows使うな」でこの記事で言いたいことの90%ぐらい終わっているのですが、他にも細々とした点が少しあるので以下少し描いておきます。まずは型指定の話です。
- groupbyするときにはカテゴリ型をなるべく使う
groupbyするときのキーが(object型ではなく) category型だと早い- 1回しか集計しないならカテゴリ型に変換する時間が無駄なので変換不要だが、大抵の場合は何度も集計処理をするのでcategory型にしておくと良い
- その他のカラムも必要な精度に応じてカテゴリ変換しておくとメモリ使用量も削減できて良い
- 自分で型を考えるのが面倒な時はKaggleコード遺産の reduce_mem_usage を使う手もあり
- 高速化されたものを紹介されている 記事
groupby の集計キーは category 型が良い
# データ読み込みの dtype 指定で category 型にしてしまっているので効果を確認するために一度object型に戻す df['location'] = df['location'].astype('object')
%%time hoge = df.groupby('location')['energy_kwh_0'].mean()
CPU times: user 59.8 ms, sys: 11 µs, total: 59.8 ms
Wall time: 59.1 ms
%%time # category 型への変換は多少時間がかかる df['location'] = df['location'].astype('category')
CPU times: user 59.4 ms, sys: 1.01 ms, total: 60.4 ms
Wall time: 64.2 ms
%%time # ただし一度変換しておくとその後の集計は早い hoge = df.groupby('location')['energy_kwh_0'].mean()
CPU times: user 11.6 ms, sys: 996 µs, total: 12.6 ms
Wall time: 16.7 ms
pd.to_datetimeはフォーマット指示するのが吉
%%time # この例は極端な例かもだが… pd.to_datetime(df['date_time'])
CPU times: user 1min 21s, sys: 223 ms, total: 1min 21s
Wall time: 1min 21s
%%time # 指定すると推論が入らないからか速い pd.to_datetime(df['date_time'], format='%d/%m/%y %H:%M')
CPU times: user 2.37 s, sys: 8.13 ms, total: 2.37 s
Wall time: 2.36 s
集計時のカラム指示
# %%time # これ終わらないので注意 # df.mean()
%%time
df.mean(numeric_only=True)
CPU times: user 8.44 ms, sys: 37 µs, total: 8.48 ms
Wall time: 9.53 ms
numpy 処理の活用
- (言うまでもないが) numpy に実装されている処理はそれで書いたほうが速い
- 上記の例のように何十倍も早くなるというわけでもないが、10-30%程度は速いのでなるべく気を使った方が良い
%%timeit df[['energy_kwh_0', 'energy_kwh_1', 'energy_kwh_2']].sum(axis=1)
10 loops, best of 5: 43.1 ms per loop
%%timeit df[['energy_kwh_0', 'energy_kwh_1', 'energy_kwh_2']].values.sum(axis=1)
100 loops, best of 5: 11 ms per loop
高速join
最後に、やや高度な高速化の話をします。
- pandas DataFrame をmergeしたい時、一定の条件を満たしていると「reindexを用いた上でconcatする」と速いというテクニックがあります。
- 一定の条件とは、「join したいDataFrameの join に利用するキーがユニークである」という内容です
- 書き方もややこしいのでこの制約を確認しつつ高速joinを行う関数を持っておくといいかもしれない
- この記事で使ってる例ぐらいのデータ量だとそんなに差が出ていないが、この方法の初出(?)の KaggleRiiidコンペのNotebook では350倍以上速くなっている(!)
%%time df_merge = pd.merge(df, df_locations, how='inner', on='location')
CPU times: user 909 ms, sys: 9.94 ms, total: 918 ms
Wall time: 920 ms
%%time
df_concat = pd.concat([
df,
df_locations.set_index('location')
.reindex(df['location'].values)
.reset_index(drop=True)
], axis=1)
CPU times: user 148 ms, sys: 3.77 ms, total: 151 ms
Wall time: 150 ms
その他 飛び道具系
- 並列化ライブラリ
- 使うならpandarallelが手軽でおすすめ
- mecabでの分かち書きみたいなどうしようなない処理を parallel_apply して使ったりしてます
- その他色々ある奴はよく知らないが、それを勉強するくらいならcudfの使い方を学んだ方が中期的に学習効率良いと思います。
- 使うならpandarallelが手軽でおすすめ
- cudf
- 多少使えない関数はあるが基本爆速
- cuml と組み合わせたりすると良い
- colab標準で入れてくれてGPU気軽に使えればいいんだけどなぁ
- colabへのインストールがむずい
- numba
- コンパイルできるように書けば速い
- ただ numba で頑張るぐらいなら cudf とか BQ でええんちゃうか
参考資料
- この記事を執筆するにあたって参考にした記事を列挙しておきます
- How to make your Pandas operation 100x faster
- Do You Use Apply in Pandas? There is a 600x Faster Way
- Fast, Flexible, Easy and Intuitive: How to Speed Up Your Pandas Projects
- Dunder Data Challenge #2 — Explain the 1,000x Speed Difference when taking the Mean
- How to simply make an operation on pandas DataFrame faster
- Make Pandas Run Blazingly Fast
- 超爆速なcuDFとPandasを比較した
- pandasで使う処理はだいたい自分のブログ記事にまとまってる
宣伝
最後に宣伝させてください。(イベント終わった後で消す)
- 僕の所属しているチームで勉強会やるのでよかったらぜひ
- 僕は現職の仕事ではメルカリアプリのホーム画面に出すレコメンデーションパーツの裏側のロジックを組んでいます。
- この記事で紹介した方法なども使いつつ膨大なログを解析してレコメンデーションロジックを組むのはなかなか面白いです
- 尋常じゃないアクセス数があるのでアプリに組み込むときの方法なども考慮してロジックを組むのは正直なかなか骨が折れる仕事ですが笑、飽き性の僕でもなかなか飽きなくて素晴らしいと思います。
- 受付が12/14までとなっているので、興味ある方はこのまま↓から申し込んで見てください
Shopeeコンペ解法を読んで勉強になったことの雑なまとめ
前置き
- Shopeeコンペの解法を読んで、勉強になることが多かったので雑にまとめたものです。
- Shopeeコンペには参加しておらず、エアプなので実際に使うときには色んな工夫が必要だとは思います。
- 参考資料からほぼ抜粋させていただいたところも多々あります。
- 問題あれば何なりとおっしゃってください。
参考資料
Solutions
ブログ記事やYoutubeなど
- shimacosさん記事
- コンペ概要や解法の丁寧な解説に加えて、何故そういう解法を思いついたのかという思考の流れや、工夫してやったけど結局多分効かなかったことも書かれていました
- この記事読まれたことがない方は、僕の記事なんか閉じてまずはこちらを読まれることを強くお勧めしますw
- Kaggle ShopeeコンペPrivate LB待機枠&プチ反省会
- コンペ終了直後に行われた日本人上位陣の方の解法解説のアーカイブ動画
- 生で聞いてる時は半分もわかりませんでしたが、その後色々調べてから再度聞くと理解が深まりとても勉強になりました
- asteriamさん記事
- 上位解法を一通りまとめてくださっています
- 英日見比べながら上位解法を読むときの理解の助けにさせていただきました
コンペ概要
- shimacosさんが書かれている記事の内容が非常に簡潔でわかりやすかったので引用させていただきます。
東南アジア最大級のECプラットフォームであるShopeeが開催したもので、データとしてはユーザが登録した商品画像と商品のタイトルが与えられます。 また、ラベルとしてはユーザが登録した商品の種別が与えられています。このラベルは、ユーザが登録したものなので、ノイズが多く載っているものになっており、同じ画像や同じタイトルでも違うラベルがついていたりします。また、この種別というのは思った以上に細かく、同じ化粧品でも50mlのものと100mlのもので違うラベルになっていたりします。 このようなユーザがつけたラベルを教師データとして、画像とタイトルのテキスト情報を用いて商品セットの中から同じ商品を抽出するモデルを作成することが今回のお題となっています。
- 与えられた画像や文書をNNでうまくベクトル化した後、それを用いて検索を行うコンペだったようですが、1st solution曰く、(embeddingを獲得するための)モデルを究極まで改善することはあまり本質的ではなく、抽出したベクトルをいかに上手く検索に利用するかが肝だったようです。
解法例 (2nd)
- 1st stage: Train metric learning models to obtain cosine similarities of image, text, and image+text data
- timm/huggingfaceをベースにベクトル取得
- それをconcatenate
- faissでインデックス化、近傍探索
- query expansion して concat (以下同じ)
- weightはsimilarityのsqrt (αQEっぽい)
- 2nd stage: Train “meta” models to classify whether a pair of items belong to the same label group or not.
- Used LightGBM and GAT (Graph Attention Networks)
勉強になったことの箇条書き
pre-train models の活用
- 画像では
timm、NLP:transformersがほぼデファクトスタンダードっぽい。 - 使い古されてるモデルから最新のモデルまで、古今東西の様々なモデルが手軽に利用できる。
- まずはこれらのモデルのfine-tuningをどう行うか、を考えるのが常套手段っぽい。
- 1st, 2nd が共にこの構成だった。
- 使っているモデルも比較的似通っていた。
timm (Github)
- 画像系のNNモデルがめちゃくちゃ頻繁に更新されている
- 上位解法で利用されていたmodelの例
- 1st
eca_nfnet_l1- nfnetを軽量化したやつ?
- 2nd
vit_deit_base_distilled_patch16_384- 画像のtransformer
dm_nfnet_f0- batch normalizationを利用しない / 2021/02に登場した新しいやつ
- 1st
- inference-code の例
# https://www.kaggle.com/lyakaap/2nd-place-solution import timm backbone = timm.create_model( model_name='vit_deit_base_distilled_patch16_384', pretrained=False) model1 = ShopeeNet( backbone, num_classes=0, fc_dim=768) model1 = model1.to('cuda') model1.load_state_dict(checkpoint1['model'], strict=False) model1.train(False) model1.p = 6.0
huggingface (ref)
- NLP界の超有名ライブラリ
AutoModelという機構(?)を使えば読込む事前学習モデルのパスを変えるだけで使いまわせる。- めちゃくちゃ便利そうなのに今まで全然知らんかった…
- マイナー言語や多言語モデルも多数存在
- 今回のECサイトはインドネシア語だったので、インドネシア語のBERTが強かったとのこと。
- models
- 1st
xlm-roberta-largexlm-roberta-basecahya/bert-base-indonesian-1.5Gindobenchmark/indobert-large-p1bert-base-multilingual-uncased
- 2nd
cahya/bert-base-indonesian-522M- Multilingual-BERT (huggingfaceのモデル名調べてない)
- Paraphrase-XLM embeddings (同上)
- 1st
- inference-code の例
# https://www.kaggle.com/lyakaap/2nd-place-solution from transformers import AutoTokenizer, AutoModel, AutoConfig model_name = params_bert2['model_name'] tokenizer = AutoTokenizer.from_pretrained('../input/bertmultilingual/') bert_config = AutoConfig.from_pretrained('../input/bertmultilingual/') bert_model = AutoModel.from_config(bert_config) model2 = BertNet( bert_model, num_classes=0, tokenizer=tokenizer, max_len=params_bert['max_len'], simple_mean=False, fc_dim=params_bert['fc_dim'], s=params_bert['s'], margin=params_bert['margin'], loss=params_bert['loss'] ) model2 = model2.to('cuda') model2.load_state_dict(checkpoint2['model'], strict=False) model2.train(False)
深層距離学習
- 概要はyu4uさんの記事に詳しい
- 以下の点が嬉しいとのこと
- 通常のクラス分類問題を学習させるだけで距離学習が実現できる
- 学習が容易なクラス分類モデルに1層独自のレイヤを追加するだけで、通常のクラス分類問題として学習が可能、ロスもcross entropyのままで良い。
- 上位のチームは大体使ってそう
- 以下の点が嬉しいとのこと
- チューニングに手こずることも
- 1stのチームはArcFaceのチューニングに相当手こずったそうで、以下の工夫をしたとのこと。
- increase margin gradually while training
- use large warmup steps
- use larger learning rate for cosinehead
- use gradient clipping
- 4thのチーム
- we also saw batch size to matter during training
- Some models seemed to be very sensitive to the learning rate
- gradient clipping may have also helped to stabilize the training.
- shimacosさん
- 序盤はなかなか学習が進まなかったりしてパラメータの調整が難しかった
- 学習率を大きくし、warmupを大きめに行うことで学習が進みやすくなった
- 学習の序盤だと普通のsoftmaxよりもクラス間の予測値の差が顕著に出ないため、学習が難しいのではないか
- 1stのチームはArcFaceのチューニングに相当手こずったそうで、以下の工夫をしたとのこと。
- 2ndは
CurricularFaceを利用- 多くのチームが使っていたArcFaceを超える性能だったとのこと
- 学習ステージに応じて、イージーサンプルとハードサンプルの相対的な重要性を自動調整?
- ArcFace に学習サンプルを賢く選ぶような機能をつけたイメージ?
- 1st: class-size-adaptive margin もある程度は使えたのこと
- google landmark でも使われてたとか
- landmarkほど多クラスではなかったためか効果は限定的だったとのこと
QueryExpansion / DataBase-side feature Augmentation
- IRにおいてクエリ及びDBを拡張するための手法
- QueryExpansion: 検索した結果を元にクエリをどんどん拡張していく
- 元々のベクトルで検索
- 検索で引っかかったアイテムのベクトルを重み付けして元のベクトルに加算
# https://www.kaggle.com/lyakaap/2nd-place-solution def query_expansion(feats, sims, topk_idx, alpha=0.5, k=2): # 引っかかった似ているアイテムへのウェイトを決める式(論文) weights = np.expand_dims(sims[:, :k] ** alpha, axis=-1).astype(np.float32) # ウェイトに応じてベクトルを加算して新しいベクトルを求める feats = (feats[topk_idx[:, :k]] * weights).sum(axis=1) return feats # img_D / img_I は一段目の検索で引っかかった画像のベクトル、インデックス img_feats_qe = query_expansion(img_feats, img_D, img_I)
- DBA(DataBase-side feature Augmentation)
- lyakaapさんのmemoより
- データベースのサンプルを、そのサンプルに対する近傍のdescriptorによる重み付き平均を取ることでrefineする。
- QEと似ている。QEはquery側をrefineするけどDBAはDB側をrefineするイメージ。そのためDBAはオフラインで一回やるだけで良くて、query searchのときには速度に影響しないのが強み。
- 何故効くのか? → descriptorがよりクラス中心に近づくから。DBAは同一クラス同士(近傍のサンプルは同一クラスに大体属しているという仮定)でよりクラス中心に引きつけ合うようなことをしている。
- lyakaapさんのmemoより
embeddingをアンサンブルするときの工夫
* 一番良かったのは、各種EmbeddingをそれぞれL2 Normalizeしてからconcatするという方法 * モデルによってEmbeddingのスケールが違うので当たり前と言えば当たり前ですが、L2 normalizeせずにconcatしてしまうとそこまで改善が得られませんでした。 * このような細かい技術は、過去コンペの解法でもしれっと書かれているだけなので覚えておくと良いかもしれません。
faiss
- Facebook Resarchが提供する近傍探索ライブラリ (Github)
- faissはGPUをフル活用して検索を高速化することもできるそうなので、このコンペとの相性が良かったのだろうか。
- 日本語のキャッチーな記事
- メルカリ社でも使われてるとのこと、ふーん。
- ベクトルの追加とそれを用いた検索のコード例
# https://www.kaggle.com/lyakaap/2nd-place-solution import faiss res = faiss.StandardGpuResources() index_img = faiss.IndexFlatIP(params1['fc_dim'] + params2['fc_dim']) index_img = faiss.index_cpu_to_gpu(res, 0, index_img) index_img.add(img_feats) similarities_img, indexes_img = index_img.search(img_feats, k)
Forest Inference
- GPUでGBMの推論を爆速にしてくれるやつ
- RAPIDS公式
- Using FIL (Forest Inference Library), a single V100 GPU can deliver up to 35x more inference throughput than a CPU-only node with 40 cores.
# 多分こんな感じで使う import treelite from cuml import ForestInference clf = ForestInference() clf.load_from_treelite_model( treelite.Model.load( '/tmp/tmp.lgb', model_format='lightgbm' ) ) clf.predict(X_test).get()
その他細かな点
Generalized Mean (GeM) Pooling
- lyakaapさんのmemo
- p=1でmean, p=∞でmaxと等しい。論文ではp=3を推奨。SPoC/MACよりも高精度。
- https://amaarora.github.io/2020/08/30/gempool.html
- GeM pooling 層は学習可能なのでpを自動的に決めることもできる
- https://paperswithcode.com/method/generalized-mean-pooling#
tokenizer
- TweetTokenizer
- カジュアルな文章のtokenizeに向いている?
NVIDIA DALI
- 画像の読み込みとリサイズが高速化される
- 参考: https://xvideos.hatenablog.com/entry/nvidia_dali_report
LightGBM特徴量 (2nd)
- 各商品のTOP50の組み合わせに対して類似度や編集距離を付与 → 同じカテゴリだったかどうかを予測するように学習
- 特徴量
- 商品同士の類似度
- 編集距離
- 各商品のタイトルの長さ、ワード数
- 各商品のtop-N類似商品のsimilarityの平均
- (これ効くのどういうお気持ちなんだろう)
- 各商品の画像サイズ
- 特徴量
punctuationの前処理
- 複数の文字(長さ1の文字列)を指定して置換する場合は文字列(str型)のtranslate()メソッドを使う。translate()に指定する変換テーブルはstr.maketrans()関数で作成する。
title.translate(str.maketrans({_: ' ' for _ in string.punctuation}))
- string: https://docs.python.org/ja/3/library/string.html
string.punctuation: String of ASCII characters which are considered punctuation characters in the C locale
- TfidfVectorizer:
token_pattern=u'(?u)\\b\\w+\\b'とかやると一文字のトークンを除外しなくなる
編集距離を一撃で出すライブラリ
- 色々あるらしい
editdistanceLevenshtein
# https://github.com/roy-ht/editdistance import editdistance editdistance.eval('banana', 'bahama') ## 2 # https://qiita.com/inouet/items/709eca4d8172fec85c31 import Levenshtein string1 = "井上泰治" string2 = "井上泰次" string1 = string1.decode('utf-8') string2 = string2.decode('utf-8') print Levenshtein.distance(string1, string2)
stemmer
import Stemmer stemmer = Stemmer.Stemmer('indonesian')
LangID
言語を特定してくれる
import langid result = langid.classify('これは日本語です') print(result) # => ('ja', -197.7628321647644)
Kaggle Riiid! コンペ参戦記
これは何?
- '20/10-'21/01にKaggleで開催されていた
Riiid! Answer Correctness Predictionの参加記録です - public 51st (0.801) → private 52nd (0.802) と順位は奮いませんでしたが、現実世界での予測タスクに即したコンペの設計(後述)や、1億行を超える豊富なデータを扱えるといった内容が非常に勉強になるコンペでした。
- Discussionに投下した内容と被りますが、自身の備忘録(と解法の供養) のためにまとめておきます。
コンペ概要
ざっくり言うと
- TOEIC勉強アプリでのユーザーの正答確率を予測するコンペ
- Code Competition (コードを提出する形式のコンペ)
- trainデータは約1億、testデータは約250万。
- ただし次項で述べるようにtestデータは見ることができない
SANTA TOEIC と言うアプリが題材でした
Riiidコンペの題材はTOEIC対策アプリっぽいかな?
— ML_Bear (@MLBear2) October 9, 2020
"Santa reached No. 1 in sales among education apps in Japan and Korea." との通り、日韓でappstore 1位取ったりしてるとのこと。https://t.co/Fm1t5Owq2k
アプリLP→https://t.co/ZJhOH9Urfk
コンペの特徴: 現実世界での予測タスクに即したコンペ設計
- 特殊なサブミット方法を採っているコンペであったため、「未来の情報を用いた特徴量を作る」「超大量の特徴量で殴る」というkaggleでありがちな(実運用しづらい)方法が塞がれていたり、新しいデータに合わせて少しづつモデルや特徴量を更新することも可能だったりと、非常に実用的なコンペだったと思います。
- サブミット方法
- 提出するコードはサブミット時に指定されたAPIを叩くように書く
- サブミット後の実行時に1バッチあたり30-50問(?)程度づつレスポンスが返ってくる
- 予測を行って提出すると、次のバッチデータが降って来る。
- そのため未来の情報を使って特徴量を生成することができない
- そのバッチには前のバッチのデータの正解ラベルも与えられている
- そのため特徴量の更新やモデルの再学習なども行える
- ただし1バッチあたり約0.55sec以下で処理しないと全体の処理時間が9時間を超えてTimeout Errorでサブミットが通らない
- そのため超大量の特徴量を使うモデルは活用しづらい (testデータを受け取ってから処理するのに大量の時間を使うため)
- コンペを主催する意義も高まりそうで、この形式のコンペが今後主流になればいいなと個人的には感じてます。
これ完全に同意する。kaggleノートブックのメモリ制約とか、特徴量生成の時間制約とかも含めてRiiidはコンペの一つの完成形だと思う。テーブルコンペはずっとこれで良いんじゃないかな〜。(初心者辛そうだが…) https://t.co/zzRwOFAbka
— ML_Bear (@MLBear2) December 7, 2020
サブミット時の厳しい時間制限から、たくさんの高速化Tipsが生まれたコンペだとも思います。
pandasのleft joinを300倍以上高速化したkaggle notebook。
— ML_Bear (@MLBear2) November 24, 2020
結合するテーブルの結合キーがユニークである制約が必要なものの、軽く書き直すだけで300倍も早くなるとはすごい…!
concatのほうが速いのは直感的にわかるけどreindex知らなかったので勉強になりました。https://t.co/NFugt6Nisr pic.twitter.com/jcHK3T9ndo
概要
- 開催期間: 2020/10/06 〜 2021/01/08
- 参加チーム数: 3,406
- 目的変数: ユーザーが問題に正答するか否か (1あるいは0)
- 与えられるデータ
- ユーザーの問題回答ログ、講義ログ
- 問題ID, 問題グループID, 問題のタグID(タグ内容は非公開), 問題を解いた後に解説を見たか否か, 問題を解くのにかかった時間 など
- 評価指標: AUC
解法
- LightGBMx2 + CatBoostx1 の加重平均アンサンブル
- 特徴量は130個ぐらい
- NN (transformer) はチームメイトが終盤に試してくれていましたが間に合いませんでした
効いた特徴量
少し工夫したなやつ
回答のヤバさを図る指標
- +0.006と自分たちが作った特徴量の中では圧倒的に光り輝いていた😇
- 作り方
- train全部を使って各問題の各選択肢がどれくらい選択されているかを計算
- 例: content_id=XXXX の選択肢1/2/3/4の選択率: 9% / 5% / 1% / 85%
- 各問題で選択率を積み上げて各選択肢のパーセンタイルを算出
- 例: ↑の例だと
- 選択肢1: 15% (=1+5+9)
- 選択肢2: 6% (=1+5)
- 選択肢3: 1%
- 選択肢4: 100% (=1+5+9+85)
- 例: ↑の例だと
- 各ユーザーの過去の選択肢のパーセンタイルをAggregation(std, avg, min, etc.)
- train全部を使って各問題の各選択肢がどれくらい選択されているかを計算
- 気持ち
- ほとんどの人が選んでいないようなヤバイ選択肢を選んでる人は多分ヤバイ
- よくできる人はたとえ間違ったとしてもヤバイ選択肢は選ばないはず
- ↑の例の選択肢3とか選ぶ人は多分ヤバイのでそのあともヤバイはず
- 多分この考えは合っててstdの集計がめちゃくちゃ効いていた
少し工夫したWord2Vec by チームメート
- ややリークしていた挙動だったが+0.004ぐらい効いていてこちらも非常に効果があった
- 作り方
- 各ユーザーごとに
問題_(正解|不正解)を並べる 問題_(正解|不正解)をword2vecでベクトル化- ユーザーの過去N問の
問題_(正解|不正解)のベクトルを平均してユーザーをベクトル化 - ユーザーベクトルと次の問題の
問題_(正解)問題_(不正解)のコサイン近似度を算出
- 各ユーザーごとに
trueskill by チームメート
- trueskillで各問題、各ユーザーの強さをスコア化
- そこからユーザーが問題に勝つ(正答する)確率を算出
- importanceは常にtopだったが+0.001ぐらい
- 最終盤に入れたため他の特徴量と食い合っていたかもしれない
- 正答の重み付き足し上げ by チームメート
- 重みは正答率の逆数として、正答を重み付きでカウント
基本的なやつ (抜粋して記載)
- 各種TargetEncoding (問題の正答率, 問題を正答できた人の割合, etc.)
- 各種ユーザーログ (過去400問の正答率, 過去400問のうち同じパートでの正答率, etc.)
- メモリの関係で過去400問だけの集計にした。800問に伸ばしてもたいして精度変わらなかったが無限にログ取ったら変わったりしたのだろうか?
- timestampのLag系特徴量
- 前に同じ問題を解いた時からの経過時間
- 前の問題からの経過時間
- timestampを加工した特徴量
- 経過時間を使う物
- 前の問題からの経過時間 / そのtask_containerにかかる平均的な時間
- 前の問題からの経過時間 / そのtask_containerにかかる平均的な時間(正答のみで集計)
- これらが効いていたのでtimestampは
問題を回答したtimestampかなと思っていたけどどうだろうか?
- SAINTの論文に載っていたラグタイムをなるべく再現した物
- 前の問題からの経過時間 - 前の問題にかかった時間
- 経過時間を使う物
- 単純なWord2Vec
- 各ユーザーごとに問題を並べる→問題を単語と見立ててword2vecでベクトル化
- パート別、正解の問題のみ、誤答の問題のみ、windowいろいろ振ってみる、などでたくさん作った
- パターンを足せば足すだけスコアがのびた印象
- 各ユーザーごとに問題を並べる→問題を単語と見立ててword2vecでベクトル化
効かなかったこと
まぁ大量にあるのですが不思議な点だけ
- tag
- タグの出現するパートの分布から、タグの仕分けはできていた。
- 文法のタグとかイントネーションのタグとか分かっていた
- にもかかわらず、いろいろ加工してモデルに入れてみたが全然効かなかった
- target encodingしたり、ユーザーの過去のタグの正答数とか数えてみたりした
- タグの出現するパートの分布から、タグの仕分けはできていた。
- Lecture
- 単純カウントなどをして入れてみたが全然活用できなかった
その他工夫した点
- stickytape
- コードはチームでGithub管理を行っていました。
- stickytapeを用いて、依存している特徴量生成コードなどをいい感じにまとめてkaggle notebookに貼り付けるスクリプトが生成されるようにチームメートが設定してくれました。
- BigQuery
- 学習時はBigQueryを使ってデータ生成を行い、うまく行った特徴量だけサブミット用に書き直しました
このコンペは仕事か?って思うぐらいたくさんSQL書きました
チームメイトが書いたSQLがとてもよく考えられて練られたものだったので思わずちょっと嫉妬してしまったw Kaggle仕事で使えない説を推進してる人に是非見てほしい。
— ML_Bear (@MLBear2) December 6, 2020
反省
まだ上位陣のソリューション読んでない中での反省なので読んだら変わるかもですが。
- NNを終盤までやらなかった(できなかった)
- DSB2019で上位陣がほぼLightGBM一本で上位に食いこめていた印象が強く、NNは後回しにしていた。
- サブミットコードの構築(ローカル特徴量の移植)にやや手間取って時間を食ってしまった。
- 別々に組んでいた特徴量がめちゃくちゃ食い合っていた
- みんなが作った特徴量をマージしたモデル作っても全然スコア上がらなくて控えめに言ってめっちゃショックだった。
- 単純足し上げで+0.006ぐらい見込んでいたのが+0.001ぐらいしか上がらなかった
- その時点でちょっと心折られてしまった感があった…。
- みんなが作った特徴量をマージしたモデル作っても全然スコア上がらなくて控えめに言ってめっちゃショックだった。
上位解法
- 続々と公開されるはずなのであとでまとめて記事にしようと思っています
Kaggleで戦いたい人のためのpandas実戦入門
はじめに
- 自分は元々pandasが苦手でKaggleコンペ参加時は基本的にBigQuery上のSQLで特徴量を作り、最低限のpandas操作でデータ処理をしていました。
- しかし、あるコードコンペティションに参加することになり、pythonで軽快にデータ処理をこなす必要が出てきたので勉強しました。
- そこで、当時の勉強メモをもとに「これだけ知っていればKaggleでそこそこ戦えるかな」と思っているpandasの主要機能をまとめました。
注記
実戦入門のつもりがほぼ辞書になってしまいました orz- pandasとはなんぞや的な内容は書いていません
(import pandasやDataFrameとは何かなど) - pandas1.0系でも動くように書いたつもりですが間違ってたらすみません
目次
- はじめに
- 目次
- Options
- DaraFrame 読み書き
- データクリーニング
- DataFrame操作
- 各種演算
- カテゴリ変数エンコーディング
- 文字列操作
- 日付系処理
- 可視化
- 並列処理
- おまけ: Excel読み書き
- pandasを身につけるには?
- おわりに
Options
jupyter notebook で DataFrame の表示が省略されないようにする。 なんだかんだ書き方をよく忘れる。
pd.set_option('display.max_columns', None) pd.set_option('display.max_rows', None)
DaraFrame 読み書き
CSVファイル
読み込み
read_csv は意外とオプションが多いのでなかなか覚えきれません。
# 基本 df = pd.read_csv('train.csv') # headerがないとき (列名は連番になる) df = pd.read_csv('train.csv', header=None) # headerがなくて自分で列名指定したいとき df = pd.read_csv('train.csv', names=('col_1', 'col_2')) # 利用する列を指定したいとき df = pd.read_csv('train.csv', usecols=['col_1', 'col_3']) # lamda式も利用可能 df = pd.read_csv('train.csv', usecols=lambda x: x is not 'col_2') # 列名: 読み込んだあとの変更 df = df.rename(columns={'c': 'col_1'}) # 型指定で読み込み (指定した列以外は自動推定) ## メモリ逼迫しているとき以外は、型指定せず read_csv して、 ## 後述の `reduce_mem_usage` を使うことも多い df = pd.read_csv('train.csv', dtype={'col_1': str, 'col_3': str}) ## 型: 読み込んだあとの変更 df = df['col_1'].astype(int) # float / str / np.int8 ... # 時間系データをparse df = pd.read_csv('train.csv', parse_dates=['created_at', 'updated_at'])
書き出し
# 基本 df.to_csv('file_name.csv') # index不要のとき (kaggle submission fileは不要なので忘れがち) submission.to_csv('submission.csv', index=False)
Pickleファイル
# 基本 df = pd.read_pickle('df.pickle') df.to_pickle('df.pickle') # データが重いときはzip化できる (が遅くて実用に耐えないらしい) ## 書き出し: 拡張子を zip や gzip にするだけでよい df.to_pickle('df.pickle.zip') ## 読み込み: read_pickle は拡張子を見て自動的に解凍処理をしてくれる df = pd.read_pickle('df.pickle.zip')
- pandas.DataFrame, Seriesをpickleで保存、読み込み
- pandas の永続化フォーマットについて調べた
- pickle / feather / parquet の比較をしている記事
- 保存時のファイルサイズ以外はあらゆる面でpickleが優れているとのこと
- ファイルサイズはparquetが小さいとのこと
メモリ使用量削減の工夫
ファイルを読み込んだ直後にメモリ使用量削減するクセを付けておくと色々はかどります。
型変更
# kaggleでよく使われる `reduce_mem_usage` でメモリ使用量削減 ## 内部では各カラムの値域に合わせて型変更を行っている ## `reduce_mem_usage` 実装は ref 参照 df = reduce_mem_usage(df) # 実践的には read_csv した直後にメモリ使用量削減を行うことも多い df = df.read_csv('train.csv')\ .pipe(reduce_mem_usage) # 余談だが、pipeを使うと可読性向上することが多い # f(g(h(df), arg1=1), arg2=2, arg3=3) df.pipe(h) \ .pipe(g, arg1=1) \ .pipe(f, arg2=2, arg3=3)
不要カラム削除
import gc # dropでも良い: df.drop('col_1', axis=1, inplace=True) del df['col_1']; gc.collect();
データクリーニング
欠損データ処理
# 欠損がある行を削除 df1.dropna(how='any') # 特定の列で欠損している行を無視 df = df[~df['col_1'].isnull()] # 埋める df1.fillna(value=0)
重複排除
# 基本 df2.drop_duplicates() # 重複しているカラムの指定 df2.drop_duplicates(['col_1']) # 残す列の指定 df2.drop_duplicates(['col_1'], keep='last') # keep='first' / False(drop all)
補間 (interpolate)
- Kaggleではあまり使わないかもだが、実務とかで役に立ちそう
DataFrame操作
DataFrame 情報表示
# 行数,列数,メモリ使用量,データ型,非欠損要素数の表示 df.info() # 行数 x 列数 取得 df.shape # 行数取得 len(df) # 最初 / 最後のN行表示 df.head(5) df.tail(5) # カラム名一覧を取得 df.columns # 各要素の要約統計量を取得 ## 数値型要素の min/max/mean/stdなどを取得 df.describe() ## カテゴリ型要素の count/unique/freq/stdなどを取得 df.describe(exclude='number') ## 表示するパーセンタイルを指定 df.describe(percentiles=[0.01, 0.25, 0.5, 0.75, 0.99])
Slice (iloc / loc / (ix))
# 基本 df.iloc[3:5, 0:2] df.loc[:, ['col_1', 'col_2']] # 行は数値で指定して、列は名前で指定する # (バージョンによっては ix でもできるが廃止された) df.loc[df.index[[3, 4, 8]], ['col_3', 'col_5']]
型による列選択
# 除外もできる df.select_dtypes( include=['number', 'bool'], exclude=['object'])
条件指定による行選択
# 基本 df[df.age >= 25] # OR条件 df[(df.age <= 19) | (df.age >= 30)] # AND条件 df[(df.age >= 25) & (df.age <= 34)] ## betweenでも書ける (あまり見ないが) df[df['age'].between(25, 34)] # IN df[df.user_id.isin(target_user_list)] # query記法: 賛否両論あるが個人的には好き df.query('age >= 25') \ .query('gender == "male"')
indexリセット
# 基本 df = df.reset_index() # 破壊的変更 df.reset_index(inplace=True) # drop=Falseにするとindexが列として追加される df.reset_index(drop=False, inplace=True)
列削除
# 基本 df = df.drop(['col_1'], axis=1) # 破壊的変更 df = df.drop(['col_1'], axis=1, inplace=True)
Numpy Array 化
# df['col_1'] のままだと index が付いてきて # 他のdfにくっつけるときにバグを引き落とすようなこともあるので # numpy array にして後続の処理を行うことも多々ある df['col_1'].values
連結・結合
連結
# concat ## 基本 (縦に積む: カラムは各DataFrameの和集合 df = pd.concat([df_1, df_2, df_3]) ## 横につなげる df = pd.concat([df_1, df_2], axis=1) ## 各DataFrameに共通のカラムのみで積む df = pd.concat([df_1, df_2, df_3], join='inner')
- pandas cheetsheet
- Reshaping Data の部分に色付きのわかりやすい図があります
- pandas.DataFrame, Seriesを連結するconcat
- concat 苦手すぎてこの記事をたぶん100回以上見てる気がします笑
結合
merge: キーを指定しての結合
# 基本 (内部結合) df = pd.merge(df, df_sub, on='key') # 複数のカラムをキーとする df = pd.merge(df, df_sub, on=['key_1', 'key_2']) # 左結合 df = pd.merge(df, df_sub, on='key', how='left') # 左右でカラム名が違うとき df = pd.merge(df, df_sub, left_on='key_left', right_on='key_right') \ .drop('key_left', axis=1) # キーが両方残るのでどちらか消す
join: indexを利用した結合
# 基本 (左結合: mergeと違うので注意) df_1.join(df_2) # 内部結合 df_1.join(df_2, how='inner')
ランダムサンプリング
# 100行抽出 df.sample(n=100) # 25%抽出 df.sample(frac=0.25) # seed固定 df.sample(frac=0.25, random_state=42) # 重複許可: デフォルトはreplace=False df.sample(frac=0.25, replace=True) # 列をサンプリング df.sample(frac=0.25, axis=1)
ソート
# 基本 df.sort_values(by='col_1') # indexでソート df.sort_index(axis=1, ascending=False) # キーを複数 & 降昇順指定 df.sort_values(by=['col_1', 'col_2'], ascending=[False, True])
argmax / TOP-N 系の処理
# 最も値が小さな行/列を見つける df['col1'].idxmax() # 最も和が小さな列を見つける df.sum().idxmin() # TOP-N: col_1で上位5件を出す → 同一順位であればcol_2を見る df.nlargest(5, ['col_1', 'col_2']) # .smallest: 下位N件
各種演算
よく使う関数基礎
# 集計 df['col_1'].sum() # mean / max / min / count / ... # ユニーク値取得 df['col_1'].unique() # ユニーク要素個数 (count distinct) df['col_1'].nunique() # percentile df['col_1'].quantile([0.25, 0.75]) # clipping df['col_1'].clip(-4, 6) # 99パーセンタイルでclipping df['col_1'].clip(0, df['col_1'].quantile(0.99))
出現頻度カウント (value_counts)
# (NaN除く) df['col_1'].value_counts() # 出現頻度カウント(NaN含む) df['col_1'].value_counts(dropna=False) # 出現頻度カウント (合計を1に正規化) df['col_1'].value_counts(normalize=True)
値の書き換え (apply / map)
Series各要素の書き換え: map
# 各要素に特定の処理 f_brackets = lambda x: '[{}]'.format(x) df['col_1'].map(f_brackets) # 0 [11] # 1 [21] # 2 [31] # Name: col_1, dtype: object # dictを渡して値の置換 df['priority'] = df['priority'].map({'yes': True, 'no': False})
DataFrameの各行・各列の書き換え: apply
# 基本 df['col_1'].apply(lambda x: max(x)) # もちろん自身で定義した関数でも良い df['col_1'].apply(lambda x: custom_func(x)) # 進捗を表示するときは # from tqdm._tqdm_notebook import tqdm_notebook df['col_1'].progress_apply(lambda x: custom_func(x))
その他の書き換え (replace / np.where)
# replace df['animal'] = df['animal'].replace('snake', 'python') # np.where df['logic'] = np.where(df['AAA'] > 5, 'high', 'low') # np.where: 複雑ver. condition_1 = ( (df.title == 'Bird Measurer (Assessment)') & \ (df.event_code == 4110) ) condition_2 = ( (df.title != 'Bird Measurer (Assessment)') & \ (df.type == 'Assessment') & \ (df.event_code == 4100) ) df['win_code'] = np.where(condition_1 | condition_2, 1, 0)
集約 (agg)
# 基本 df.groupby(['key_id'])\ .agg({ 'col_1': ['max', 'mean', 'sum', 'std', 'nunique'], 'col_2': [np.ptp, np.median] # np.ptp: max - min }) # 全ての列を一律で集約したいときはリスト内包表記で書いてしまっても良い df.groupby(['key_id_1', 'key_id_2'])\ .agg({ col: ['max', 'mean', 'sum', 'std'] for col in cols })
集約結果の活用例
ほぼイディオムだが、最初は慣れないと処理に手間取るので例を書いておく。
# 集約 agg_df = df.groupby(['key_id']) \ .agg({'col_1': ['max', 'min']}) # カラム名が max / min になり、どのキーのものか区別できないので修正する # マルチインデックスになっているのでバラして rename する agg_df.columns = [ '_'.join(col) for col in agg_df.columns.values] # 集約結果はindexにkey_idが入っているのでreset_indexで出す agg_df.reset_index(inplace=True) # key_idをキーとして元のDataFrameと結合 df = pd.merge(df, agg_df, on='key_id', how='left')
ピボットテーブルによる集計
pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'], aggfunc={'D': np.mean, 'E': [min, max, np.mean]}) # D E # mean max mean min # A C # bar large 5.500000 9.0 7.500000 6.0 # small 5.500000 9.0 8.500000 8.0 # foo large 2.000000 5.0 4.500000 4.0 # small 2.333333 6.0 4.333333 2.0
ループを回さず配列同士の演算
列方向の平均値との差分を算出する時に便利です
# `df['{col}_diff_to_col_mean] = df['{col}'] - df['{col}'].mean()` 的な処理を一括でやる時 df.sub(df.mean(axis=0), axis=1) # sub 以外にも add / div / mul (掛け算) もある # 以下は `df['{col}_div_by_col_max] = df['{col}'] / df['{col}'].max()` の一括処理 df.div(df.max(axis=0), axis=1)
ビン詰め (cut / qcut)
# df['col_1']の最小値と最大値の間を4分割 → その境界を使ってビン詰め # つまり、各ビンに含まれる個数がバラける pd.cut(df['col_1'], 4) # df['col_1']の要素数を4等分してビンを作る → その後に境界を求める # つまり、ビンの間隔がバラける pd.qcut(df['col_1'], 4)
- ヒストグラム可視化については詳しく 後述 した
- pandasのcut, qcut関数でビニング処理(ビン分割)
時系列データでよく使う処理
shift: 行・列方向に値をずらす
# 2行下にずらす df.shift(periods=2) # 1行上にずらす df.shift(periods=-1) # 2列ずらす (あまり使わない) df.shift(periods=2, axis='columns')
rolling: 移動平均などの算出
# window幅=3の窓関数により合計値を算出 df['col_1'].rolling(3).sum() # 複数の df['col_1'].rolling(3) \ .agg([sum, min, max, 'mean'])
cumsum: 累積和
同様の関数に cummax, cummin もある
# df # A B # 0 2.0 1.0 # 1 3.0 NaN # 2 1.0 0.0 # 上記のdfの累計和を算出 df.cumsum() # A B # 0 2.0 1.0 # 1 5.0 NaN # 2 6.0 1.0
diff, pct_change: 行・列の差分・変化率を取得
# 例で使うdataframe # col_1 col_2 # 0 1 2 # 1 2 4 # 2 3 8 # 3 4 16 # 基本: 1行前との差分を算出 df.diff() # col_1 col_2 # 0 NaN NaN # 1 1.0 2.0 # 2 1.0 4.0 # 3 1.0 8.0 # 2行前との差分算出 df.diff(2) # col_1 col_2 # 0 NaN NaN # 1 NaN NaN # 2 2.0 6.0 # 3 2.0 12.0 # 負の数も指定可能 df.diff(-1) # col_1 col_2 # 0 -1.0 -2.0 # 1 -1.0 -4.0 # 2 -1.0 -8.0 # 3 NaN NaN # 変化率を取得するときは `pct_change` df.pct_change() # col_1 col_2 # 0 NaN NaN # 1 1.000000 1.0 # 2 0.500000 1.0 # 3 0.333333 1.0 # 計算対象がdatetimeの場合は頻度コードで指定可能 # 以下の例では `2日前` のデータとの変化率を算出 df.pct_change(freq='2D')
時間単位での集約
# 5分おきに平均、最大値を集計 # 頻度コード `min` `H` などの詳細は ref.2 に非常に詳しいので参照のこと funcs = {'Mean': np.mean, 'Max': np.max} df['col_1'].resample("5min").apply(funcs)
カテゴリ変数エンコーディング
カテゴリ変数エンコーディングの種類についてはこの資料が詳しい
One-Hot Encoding
# この DataFrame を処理する # name gender # 0 hoge male # 1 fuga NaN # 2 hage female # prefixを付けることでなんのカラムのOne-Hotかわかりやすくなる tmp = pd.get_dummies(df['gender'], prefix='gender') # gender_female gender_male # 0 0 1 # 1 0 0 # 2 1 0 # 結合したあと元のカラムを削除する df = df.join(tmp).drop('gender', axis=1) # name gender_female gender_male # 0 hoge 0 1 # 1 fuga 0 0 # 2 hage 1 0
Label Encoding
from sklearn.preprocessing import LabelEncoder # trainとtestに分かれているデータを一括でLabelEncodingする例 cat_cols = ['category_col_1', 'category_col_2'] for col in cat_cols: # 慣例的に `le` と略すことが多い気がする le = LabelEncoder().fit(list( # train & test のラベルの和集合を取る set(train[col].unique()).union( set(test[col].unique())) )) train[f'{col}'] = le.transform(train[col]) test[f'{col}'] = le.transform(test[col]) # label encoding したらメモリ使用量も減らせるので忘れずに train = reduce_mem_usage(train) test = reduce_mem_usage(test)
- 注記
- 上記方法だとtestにのみ含まれるラベルもencodingされてしまう
- 気持ち悪い場合は、trainにないものは一括で
-1とかに書き換えてしまう (個人的にはあまり気にしていないので正しいやり方かどうか不安…。)
- kaggle本実装
- kaggle本ではtrainに出てくるものだけでLabelEnconding
Frequency Encoding
for col in cat_cols: freq_encoding = train[col].value_counts() # ラベルの出現回数で置換 train[col] = train[col].map(freq_encoding) test[col] = test[col].map(freq_encoding)
Target Encoding
# 超雑にやるとき (非推奨) ## col_1の各ラベルに対して target(correct) の平均値とカウントを算出 ## 一定のカウント未満(仮に1000件)のラベルは無視して集計する、という例 target_encoding = df.groupby('col_1') \ .agg({'correct': ['mean', 'count']}) \ .reset_index() \ # 少数ラベルはリークの原因になるので消す .query('count >= 1000') \ .rename(columns={ 'correct': 'target_encoded_col_1', }) \ # カウントは足切りに使っただけなので消す .drop('count', axis=1) train = pd.merge( train, target_encoding, on='col_1', how='left') test = pd.merge( test, target_encoding, on='col_1', how='left')
- 上記の例は非常に雑な実装です。真面目にやるときはKaggle本の実装を読んでFoldごとに計算しましょう
文字列操作
pandas official method list にたくさん載っているので一度目を通すことをおすすめします。
基本
# 文字数 series.str.len() # 置換 series.str.replace(' ', '_') # 'm' から始まる(終わる)かどうか series.str.starswith('m') # endswith # 表現を含んでいるかどうか pattern = r'[0-9][a-z]' series.str.contains(pattern)
クリーニング
# 大文字/小文字 series.str.lower() # .upper() # capitalize (male → Male) series.str.capitalize() # 英数字抽出: 最初の適合部分だけだけ ## マッチが複数の場合はDFが返ってくる ## extractall: すべての適合部分がマルチインデックスで返ってくる series.str.extract('([a-zA-Z\s]+)', expand=False) # 前後の空白削除 series.str.strip() # 文字の変換 ## 変換前: Qiitaは、プログラミングに関する知識を記録・共有するためのサービスです。 ## 変換後: Qiitaは,プログラミングに関する知識を記録共有するためのサービスです. table = str.maketrans({ '、': ',', '。': '.', '・': '', }) result = text.translate(table)
日付系処理
基本
# 基本: 読み込み時に変換忘れたときとか df['timestamp'] = pd.to_datetime(df['timestamp']) # 日付のリストを作成 dates = pd.date_range('20130101', periods=6) # 日付のリストを作成: 秒単位で100個 pd.date_range('20120101', periods=100, freq='S') # 日付でフィルタ df['20130102':'20130104'] # unixtime にする df['timestamp'].astype('int64')
高度な日付抽出
- pandasにはとても複雑な日付抽出の仕組みが実装されており、
毎月の第4土曜日や月初第一営業日といった抽出も一瞬です。(日本の祝日が対応していないので後述のjpholidayなどで多少変更は必要ですが。) - pandasの時系列データにおける頻度(引数freq)の指定方法 に詳しいので、日付関係の実装が必要な際はぜひ一読されることをおすすめします。
# 月の最終日を抽出する pd.date_range('2020-01-01', '2020-12-31', freq='M') # DatetimeIndex(['2020-01-31', '2020-02-29', '2020-03-31', '2020-04-30', # '2020-05-31', '2020-06-30', '2020-07-31', '2020-08-31', # '2020-09-30', '2020-10-31', '2020-11-30', '2020-12-31'], # dtype='datetime64[ns]', freq='M') # 2020年の第4土曜日を抽出する pd.date_range('2020-01-01', '2020-12-31', freq='WOM-4SAT') # DatetimeIndex(['2020-01-25', '2020-02-22', '2020-03-28', '2020-04-25', # '2020-05-23', '2020-06-27', '2020-07-25', '2020-08-22', # '2020-09-26', '2020-10-24', '2020-11-28', '2020-12-26'], # dtype='datetime64[ns]', freq='WOM-4SAT')
祝日判定
- pandasではないしkaggleでも使うことも(たぶん)ありませんが、実務上便利なので掲載しておきます。
- jpholiday official
import jpholiday import datetime # 指定日が祝日か判定 jpholiday.is_holiday(datetime.date(2017, 1, 1)) # True jpholiday.is_holiday(datetime.date(2017, 1, 3)) # False # 指定月の祝日を取得 jpholiday.month_holidays(2017, 5) # [(datetime.date(2017, 5, 3), '憲法記念日'), # (datetime.date(2017, 5, 4), 'みどりの日'), # (datetime.date(2017, 5, 5), 'こどもの日')]
可視化
デザインを綺麗にするおまじない
このQiita記事に載っているおまじないを書いておくと、グラフがとても綺麗になるのでとてもおすすめです。
import matplotlib import matplotlib.pyplot as plt plt.style.use('ggplot') font = {'family' : 'meiryo'} matplotlib.rc('font', **font)
シンプルなグラフ
import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt # 基本 df['col_1'].plot() # 複数のカラムのプロットを 2x2 のタイル状に表示 # (カラム数がタイル数を超えていると怒られる) df.plot(subplots=True, layout=(2, 2)) # 上記でX軸,Y軸の共通化 df.plot(subplots=True, layout=(2, 2), sharex=True, sharey=True)
ヒストグラム
# ヒストグラム df['col_1'].plot.hist() # binを20に増やす / バーの幅を細くして間を開ける df['col_1'].plot.hist(bins=20, rwidth=.8) # X軸のレンジを指定 ## 0-100歳を5歳刻みで表示するイメージ df['col_1'].plot.hist(bins=range(0, 101, 5), rwidth=.8) # ヒストグラムが重なる時に透過させる df['col_1'].plot.hist(alpha=0.5) # Y軸の最小値・最大値を固定 df['col_1'].plot.hist(ylim=(0, 0.25))
箱ひげ図
df['col_1'].plot.box()
分布図
df.plot.scatter(x='col_1', y='col_2')
並列処理
- pandasでの処理は残念ながら速くはないと思います。BigQuery等と比較すると残念なレベルです。(まぁ処理の速さそのものを比較するのはアンフェアですが…。)
- 大量の特徴量を全て正規化するときや、大量の要素にmapをかける時とかは並列処理を駆使すると便利だと思います。
from multiprocessing import Pool, cpu_count def parallelize_dataframe(df, func, columnwise=False): num_partitions = cpu_count() num_cores = cpu_count() pool = Pool(num_cores) if columnwise: # 列方向に分割して並列処理 df_split = [df[col_name] for col_name in df.columns] df = pd.concat(pool.map(func, df_split), axis=1) else: # 行方向に分割して並列処理 df_split = np.array_split(df, num_partitions) df = pd.concat(pool.map(func, df_split)) pool.close() pool.join() return df # 適当な関数にDataFrameを突っ込んで列方向に並列処理する df = parallelize_dataframe(df, custom_func, columnwise=True)
- Make your Pandas apply functions faster using Parallel Processing (初出は別の記事だったと思いますが見当たらなかった…。)
'20/07/28 追記
- pandaparallelやswifterという並行処理を行ってくれるライブラリが充実してきているようです。
- 今後はこちらを使うのが良いかもしれません。
- 参考記事: たった数行でpandasを高速化する2つのライブラリ(pandarallel/swifter)
おまけ: Excel読み書き
kaggleでは使わないけど実務で使う人一定数いる? (僕は使ったことない)
# write df.to_excel('foo.xlsx', sheet_name='Sheet1') # read pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA'])
pandasを身につけるには?
まずは、おとなしく公式Tutorialに載ってるようなmaterialを以下のような順番で一通り回るのが最速かと思います。(可視化以外)
実践的な問題をやりたいときは前処理大全をやるのも良いかもですが、Kaggleコンペに参加する場合は公開Notebookを見ながら練習する程度でも十分かと思います。
リンク
おわりに
Kaggle関係の色々な記事を書いているので、良かったら読んでみてください〜。
実践的なTips集
コンペ参戦記
Kaggle Data Science Bowl 2019 上位解法まとめ
編集履歴
- '20/01/28: 3rd solutionを追加
これはなに?
- Kaggleで10/24-1/23に開催されたData Science Bowl 2019コンペの上位解法まとめです。
- 1/27時点で公開されている10位以内の解法をまとめてみました。
- Shake-up/downの激しいコンペでしたが、上位入賞されている方の解法には学ぶところが多く、上位に入るべくして入った方が多い印象でした。
- 流し読みしてまとめたので、間違っているところとかお気づきの点あればご指摘ください。
- 金メダル圏内のものがあと4つぐらい公開されていたので後で足そうと思います。
1st
Stats
private 0.568 / public 0.563
要約
- LightGBMのシングルモデル(!)
- Foldごとにシードを変えた5Fold
詳細
Validation
- LBが不安定なので見なかった
- 以下2つのValidationSetを利用した
- GroupK CV (installation_id / 5x5Fold)
- QWKが不安定だったので加重平均RMSEを採用した
- weight: the weight is the sample prob for each sample (We use full data, for the test part, we calculate the expectation of the sample prob as weight). (Assessmentが何回あったか、の逆数を取っている?)
- Nested CV
- 上記CVは直感に反する結果が出ることがあった
- そのため、手元でTrainを分割してチェックに使った
- 疑似train: 全ログを使った1400ユーザー
- 疑似test: ログを一部打ち切った2200ユーザー
- これを50-100回行って、(testの評価の?)平均をValidationとして確認した
- GroupK CV (installation_id / 5x5Fold)
Feature Engineering
量
- 2万個ぐらい特徴量を作って、null importanceで500個まで削った
内容
- 同じAssessmentか、類似したゲームに関連する特徴量が非常に大切だった。
(基本的にゲーム内の順序をもとに、ゲームが
どのAssessmentと似ているかをマッピングした。) - mean/sum/last/std/max/slope を true attempt, correct true, correct feedback に対して算出した。
ログデータを以下のように分割して特徴量を作った
- 全履歴
- 過去5/12/48時間
- 前回のAssessmentから現在まで
Eventインターバル特徴量を作り、mean/lastをevent_idやevent_codeでグルーピングして算出した。
- いくつかのEventインターバル特徴量はかなり効いていた
- Videoスキップ特徴量を作った
clip eventインターバル / clip時間で算出- clip時間はオーガナイザーが出してくれてたもの
event_id / event code組み合わせに対する特徴量event_code2030_misses_mean
Feature Selection
- 重複した特徴量の削除
- Adversarial AUC が0.5になるように削除
- null importance (TOP500に)
Model
- testでaccuracy_groupがわかるものはtrainに使った
- trainにはRMSEを使い、validationには加重平均RMSEを使った
Ensemble
- 行っていない
- 0.8xLightGBM+0.2xCatBoostのアンサンブルモデルはprivate0.570だったが 最終サブには使っていない(手元のCVが悪かったから)
2nd
Stats
private 0.563 / public 0.563
要約
- LightGBM / CatBoost / NN のアンサンブル
- 基本的な特徴量に加え、経過によって減衰させた特徴量やword2vecを活用。
- 集約する前のログの各行を予測する特徴量も活用。
詳細
Validation
- 1ユーザーあたり1サンプルになるようにリサンプル
- StratifiedGroupKFold, 5-fold
Feature Engineering
基本的な特徴量
- session, world, types, title, event_id, event_code をワールド別や全体でカウント
- sessionごとに半減して減衰させてカウント
- 経過日数で減衰させてカウント
- num_correct, num_incorrect, accuracy, accuracy_groupに対して大量の統計値を算出
- 前回のAssessmentからの経過時間
Word2Vec
- Assessmentまでのタイトルの履歴を文章とみなす → word2vecでタイトルをベクトル化 → 集計
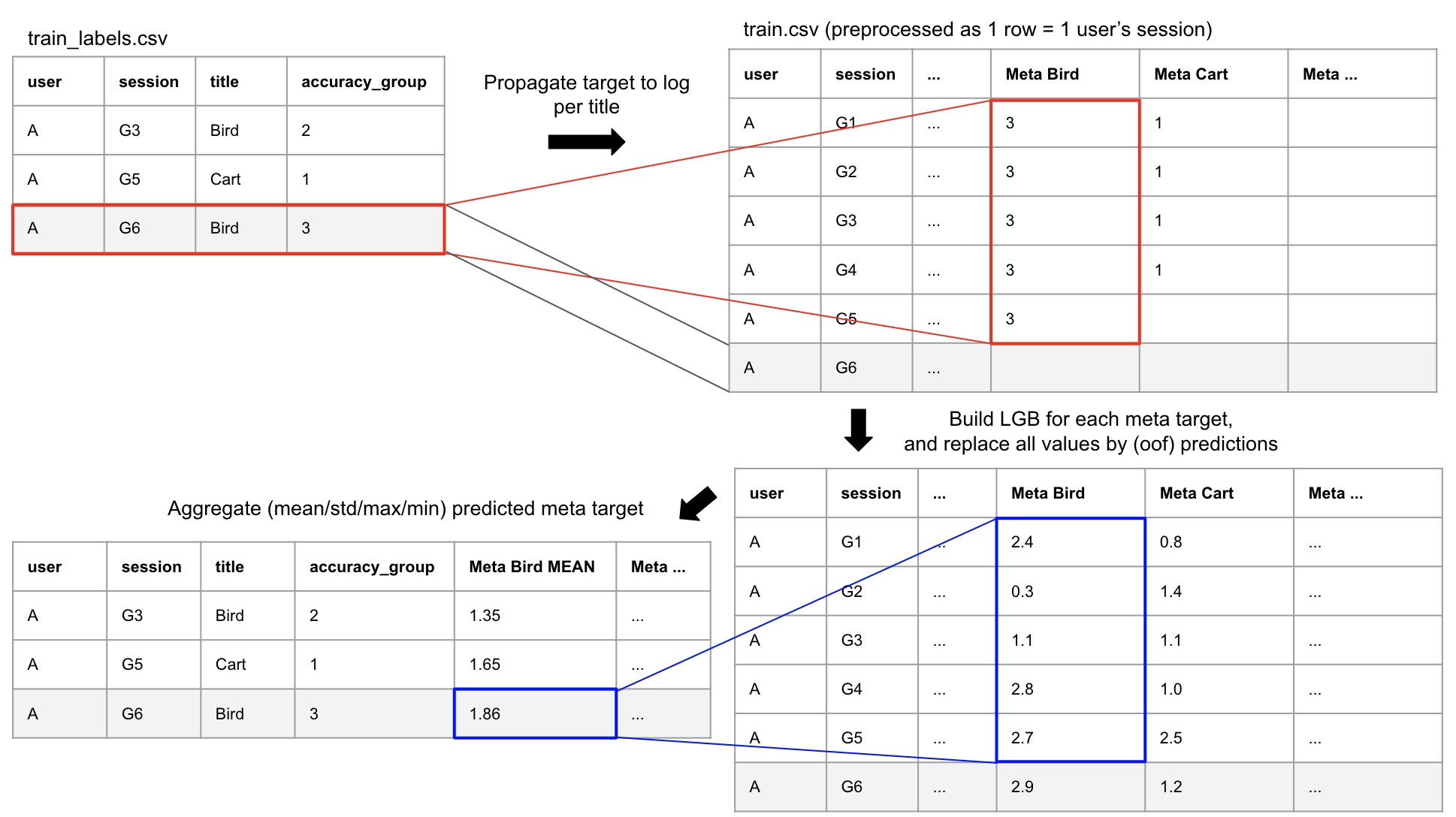
Meta Features
- ログデータの各行にAssessmentの評価を付与→予測→集約
 出典
出典
Feature Selection
- 重複した特徴量の削除
- 相関が高い特徴量の削除
- null importance (TOP300)
Model / Ensemble
- アンサンブル: 0.5 x LightGBM + 0.2 x CatBoost + 0.3 x NN
- 各モデルは 5seed averaging
3rd
- 5-fold TRANSFORMER Model(Single Model)
- private LB 0.562 / public LB 0.576
- 韓国の旧正月で忙しいからまた書くわ、とのことです。
('20/01/28追記: 書いてくださったので追記しました)
3rd solution - single TRANSFORMER model
前置き(意訳)
- DNNで問題を解くのが好きだからなるべく多くの問題をDNNで解いている
- データそのものの理解よりはデータの構造に着目し、なるべく情報の欠損がないようにモデルに入力するよう心がけている。
- 言い換えると、特徴量エンジニアリングよりもデータにより良くフィットするNNのネットワークデザインの発見により注力している。
詳細
注目すべき点
- 位置関係の情報はCVを下げたので、BERT/ALBERT/GPT2といったposition-embeddingを使うものは精度が良くなかった。
- そのため、position-embeddingを使わないTransformerモデルを組んだ
Pre-processing
- game_sessionごとにevent_code/event_id/accuracy/max_roundなどのカウントを集計
- game_sessionを単語に見立ててシーケンスとしてモデルに入力する
Model
- 100 sessionを入れた (短いシーケンスはPADで埋めた)
- embeddingの作り方
- Categorical変数: ['title', 'type', 'world']
- 個別にembed→concat→nn.linearで次元削減
- 連続値の変数: ['event_count', 'game_time', 'max_game_time'] (+accuracy/max_round?)
- np.log1pで正規化→nn.linearで直接embed
- Categorical変数: ['title', 'type', 'world']
- params
- optimizer: AdamW
- schedular: WarmupLinearSchedule
- learning_rate: 1e-04
- dropout: 0.2
- number of layers : 2
- embedding_size: 100
- hidden_size: 500

{kind=link}
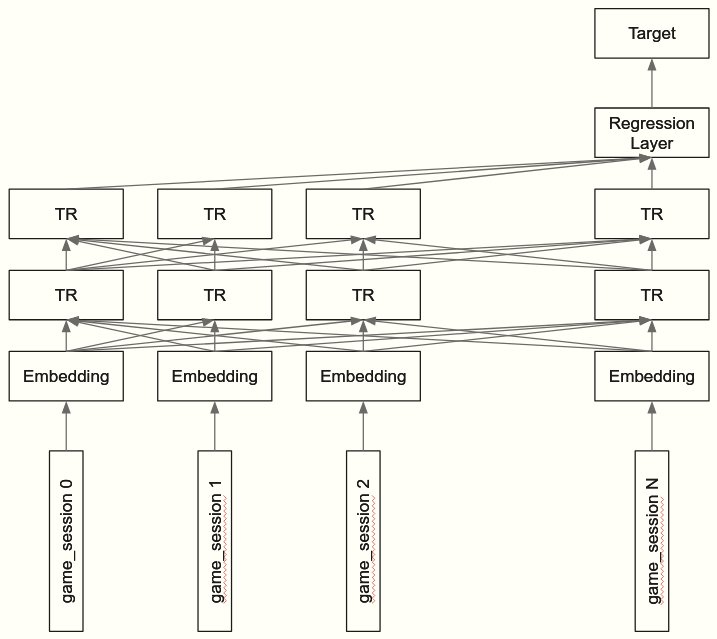{kind=link}
Loss function
- accuracy_groupの定義を以下のように再構成した
new_accuracy_group = 3 * num_correct - num_incorrect (num_incorrect: contrained not to exceed 2) (new_accuracy_group >= 0 の制約も入れてる、はず…?)
- [num_correct, num_incorrect] をターゲットとして、mseをmodified_lossとして扱った。
- accuracy_group もtargetに入れて、最終的に以下のようにしてaccuracy_groupの予測とした
new_accuracy_group = 3 * num_correct_pred - num_incorrect_pred final_accuracy_group = (accuracy_group_pred + new_accuracy_group) / 2
Data Augumentation
- 多く(30以上)のゲームセッションがあるユーザーのセッションをランダム除去した
- Train: 古い順に最大50%をランダム除去
- Test: 同60%をランダム除去
Data Augumentation (pre-train用)
- Game typeのセッションからpre-train用の学習データを生成した
- Gameセッションのcorrectからnum_correct/num_incorrect/accuraby_group(のようなもの)を作ってデータを増幅
- 41,194のデータをtrainに加えることが出来た
- 学習方法
- pre-train: original label + 上記の学習データ
- fine-tuning: original labelのみ
4th
Stats
- private 0.561 / public 0.572 (NNのブレンド)
- private 0.560 / public 0.566 (3階建てStacking)
詳細
Validation
色々頑張ったけどうまく行かなかったからごく普通にやった
(installation_idのGroupKですらなかった)
Feature Engineering
- testでaccuracy_groupがわかるものはtrainに使った
- 決定木系にいれると悪化したので使わなかった
- いくつかのClipやタイトルは非常に重要だった
- EventシーケンスのTfIDFを活用
- 各event_idをtitle + event_code + correct_flag + incorrect_flagに変換 → ユーザーのシーケンスを文章とみなす → TfIDF
- Assessment, タイトル, Assessmentの評価, だけにTfIDF使っても効かなかった
- NNにはNNに適した特徴量を出すように心がけた
- タイトルのembedding (7次元)
- タイトルの正解/不正解数およびその比率
- タイトル開始時間からの経過時間(秒)
- 以前のタイトルの正解/不正解数およびその比率
Model / Ensemble
3階建てStacking (NNブレンドよりも弱かった)
- RNNx3, lgbm, catboost
- ダブルクロスバリデーション (5x5)
- MLP(x100 starts averaging), Lightgbm(x100 seed averaging)
- Ridge
- RNNx3, lgbm, catboost
全てのモデルは回帰で学習させた
- code(NN)
7th
Stats
Private 0.559 / Public 0.559 / CV 0.575
要約
- 特徴量エンジニアリングが肝だった。最後は51特徴量を使った。(150個から削った)
0.3 LGB, 0.3 CATB, 0.4 NNのアンサンブルだった- 20Foldのバギングを全モデルに適用し、NNはさらに3seed averagingを行った
- testでaccuracy_groupがわかるものはtrainに使った
- Validationではテストセットの構造を考慮して、各ユーザーから1Assessmentをランダム抽出した。
8th
Stats
Private 0.558 / Public 0.556
要約
- シンプルな3層MLP(256x256x256)
詳細
Validation
- 5 GroupKFold
- inversely weighted oof qwk をウォッチしていた
- discussionに書いた、らしい、
Feature Engineering
- Preprocess
- Log transform → std transform
- fillna with zeros
- NaNだったことを示す新たな特徴量を追加
- 2サブのうち片方はtestでaccuracy_groupがわかるものをtrainに使った
- 使ったサブ: 0.559 private
- 使わなかったサブ: 0.552 private
- 主要な特徴量 (8thより上位にあったものは省く)
- titleのdurationが16分より長いものはクリップし、フラグを立てた。
- 子どもたちが16分連続で同じタイトルをやってるのは考えづらい
- titleの平均ミスをround_durationで割ったもの
- リピート特徴量
- titleのdurationが16分より長いものはクリップし、フラグを立てた。
Feature Selection
- null importance
- 1100特徴量を作って216個を選んだ
Model
- シンプルな3層MLP(256x256x256) x 9models(seed違いだけ?)
- 各層でBatch Normalization / Dropout 0.3
- 3xleaky Relu + 1linear
- ecpochは63/65/68と僅かに変えた
- Optimizer: Adam / BatchSize: 128
- learning_rate: 0.0003 w/cyclic decay
- cyclic decay: コードが共有されている
- accuracy_groupに加えて、3 x sqrt(accuracy)も目的関数として利用
- 離散値より多くの情報をモデルが学習できるように
- だが、あまり大きな影響はなかったとのこと
- アンサンブル
- 9models x 2outputs = 18prediction のブレンディング
- code
その他
- thresholdは25回回してCVが一番良かったものを選んだ
- trainのtarget分布に合わせるよりも最適化したほうが良かった
9th
Stats
要約
- ほぼaggregation特徴量で特徴量エンジニアリング
- いくつかの多様なモデルを作ってStacking
- 巨大なランダムサーチによるしきい値探索
詳細
Model
- Stacking が非常に効いた
- LightGBM x 7 + NN x 1 → Ridge
- LightGBM
- gbdt/goss/dart
- targetをいくつか利用した
- accuracy_group
- accuracy
- accuracy_group > 2
- accuracy_group > 1
- accuracy_group > 0
Threshold tuning
- 公開KernelのOptimizedRounderは初期値に依存し、局所最適解に陥る挙動が多かった。
- そのため、truncateしたtrainをランダムサーチするようにした。
10th
詳細
Validation
- StratifiedKFold 10fold
- 各installation_idから1サンプルづつ(?)ランダム抽出
- 各Foldで51validation setsを利用
- 1つはearly_stopingに
- 残り50個でqwkの平均を取ってvalidation score算出する
Feature Engineering
- 3000-5000個ぐらい作って300個を利用した
- magic featureはなかったと思う
- 主要な特徴量 (10thより上位にあったものは省く)
- 正規化したaccuracy系特徴量
- タイトルごとに難易度が違うのでaccuracy系特徴量を正規化したものも利用した
- 例: (Accuracy - Accuracy_mean_per_title) / Feature_std_per_title
- タイトルごとに特徴量を作った
- 例:
target_distances length in Air Show - 多すぎて10タイトル分作って挫折した
- 例:
- 正規化したaccuracy系特徴量
Feature Selection
- LightGBMのfeature_importanceを元に300個を選んだ
- 各Foldで50個のデータセットを作り、5iterationごとにLightGBMのinit_modelパラメーターを使ってデータセットを変えた。(よくわからなかった…)
Model
- LightGBM x 6seed averaging
- feature_fractionは1.0にした
- タイトルごとに平均正答率が違うので全ての木で使うのが良かったのだろう
Threshold
- local CV が最大化するしきい値を固定しこれをprivateでも利用した
Kaggle Data Science Bowl 2019 参戦記 〜10万ドルの夢を見た話〜
これはなに?
- Kaggleで10/24-1/23に開催されたData Science Bowl 2019コンペの参加記録です
- 子供向けの教育アプリのログデータを元に、子供たちが課題をどれくらいの精度で解くことができるかを推定するタスクでした。
- 優勝賞金10万ドルの大盤振る舞いなコンペで、個人で最高5位まで順位が上がったときにはなかなかいい夢を見ることができました。
- ただ、評価指標の特性及びpublicLB(暫定順位)の算出に利用するデータ数不足などから、暫定順位(publicLB)と最終順位(privateLB)が激しく入れ替わるコンペでした。
- 評価指標に振り回されてアタフタした挙げ句、public 17thからprivate 56thと大きく順位を下げるというあまりよろしくない結果に終わってしまったのですが、反省も込めてやったことのメモを残しておきます。
いい夢見ていたときのツイート
捨てサブのつもりで投げたサブで、なんかすごいところまで来てしまった…。 pic.twitter.com/2zudPLf4ut
— ML_Bear (@MLBear2) 2020年1月11日
やったこと
コンペに参加するまで
- 昨年10月のIEEEコンペで初めて金メダルを取れたのですが、コンペの締切が終了直前に延長されるなどのトラブルから、大変に疲弊していました。
- なので、kaggleしばらくいいやと思って少しkaggleを休んでいましたが、12月に参加したKaggle Days Tokyo のオフラインコンペが楽しくてテーブルコンペ欲が復活してきました。(Kaggle Days Tokyo オフラインコンペ参戦記)
- そこで、年末年始時間があったので軽くKernelやDiscussionを見てみると、以下のような工夫が何も言及されていなかったので、これやるだけでもまぁまぁ行けるかな、とか思って参加してみることにしました。
- test-set内でAccuracyGroupを特定できるデータをtrainに利用する
- targetを変えたモデルを活用する
- accuracyそのもの
- そもそも正解するかどうか
- 4100(4110)イベントが何回起こるか
※ QWKは揺れる指標と聞いていたことが合ったので、ワンチャン揺れてソロ金あるかも、という打算が合ったのは書くまでもないと思います笑。
ワンチャンでソロ金取れたらええ感じやん〜、とか思ってた頃のツイート。これが3週間前とか信じられない。
どれくらい時間かけれるかわからないけど、とりあえず年末年始暇なのでDSBはじめてみた。
— ML_Bear (@MLBear2) 2020年1月2日
コードコンペ初めてなんだけど、コードや特徴量管理とかがなかなか辛そう。これに慣れるだけで終わっちゃうかもw
コンペ参加直後
- まずデータざっくり見た後、Kernelをベースにして基礎的な特徴量を作りました。
- ベースkernel
- installation_id全体でSUM取る、みたいなやつとかは当然抜きました。(最新版とかだと消えてるかも)
- adjust_factorとかのあたりがよくわからなかったので無視しました。
CV構築
- trainはtestに比べてやたらプレイ回数が多いユーザーが散見されたので削らないといけないと思っていました。
そのため、Adversarial Validation をもとにtestと乖離してそうな上位30%程度のログを特定し、以下の処理に活用しました。
- QWKのしきい最適化への活用
- testと乖離していないtrainのデータから、testの分布に合わせて500回程度サンプリングを行って評価データセット群を作り、QWKのしきい値最適化を行いました。
- 500って適当に決めたけど、そんな感じでサンプリングしている人は多かったイメージです。
- trainとtestの分布がどれくらいずれてるかわからなかったのと、threshold optimizerの挙動が不安定に感じたので平均化したかった。
- モデルの評価への活用
- 上記と同じデータセット群を用いて、RMSEの平均を取ってモデルの精度の確認を行いました。
- early_stoppingからの排除
- 学習時のValidationSetから削除してearly_stoppingの参考にしないようにしました
- TrainSetから消すテストもしてみましたが全然ダメだったので学習には使いました。
- QWKのしきい最適化への活用
上記方針はTrainをhold-outして適当に削ったもので手元で実験しながら決めました
- testをうまく再現出来ていたか微妙なのですが、何もないよりはマシかなと信じてやってました。
- IEEEコンペでチームメンバーがやってたのを学んでたので参考にしてやりました。
Data Augumentation
- test-set内でAccuracyGroupを特定できるデータをtrainに利用しました。
- 手元の数値は全面的に良くなるのですが、publicLBがなぜか下がっていました。
- そのため、最後の最後で消してしまいました。-0.004ぐらいのロスでした。最終サブの片方では残せばよかった。
Private Dataset Probing
- Assessment1回もやったことない人がどれくらいいるのか知りたかったので少しだけ行いました。
- publicより結構多かったので、publicはあまり参考にしないようにしました。(結局最終的に参考にしたのですが)
Feature Engineering
以下を行って、ベースから取ってきたものと合わせて1150個ぐらいになりました。ただ、実質3日もやってないのでこのあたりもっとやりたかった。
- ベースのKernelにこれは効くでしょってやつを足していきました。
- 同じタイトルの過去の成績、イベントカウント
- 同じワールドの(以下同じ)
- 途中のゲームの評価を詳しく
- 課題ごとの correct rate
- 4020/4025系イベントの集計
- correct系の集計
- clip length
- 他に独自のものをいくつか足しました
- target encoding
- title (≒タイトルの難易度)
- title x 何回目のトライか
- 別のモデルで予測した値を特徴量として戻す
- 予測したもの
- accuracy(mean of correct)そのもの
- 4100(4110)イベントが何回起こるか
- そもそも正解するかどうか
- これは特徴量として利用しましたが、最終アンサンブル時のStackingの1モデルとして使っても良かったかも。
- keeeeei79さんはStackingのモデルとして利用したらしい。(正規化なども特にせず)
- 予測したもの
- word2vec: event_id(+correct)を単語としてみなす → ユーザーごとにつなげて文章にする → event_id をベクトル化 → SWEM
- 比較的よく効いてました
- target encoding
- 捨てたやつ
- PageRank
- titleやevent_idの遷移をグラフ化 → AssessmentのAccuracyGroupを伝搬させtitleなどの重要度を算出 → ユーザーごとに集計
- feature importancesで上位に上がってくるのですが(publicLB)スコアにはほぼ無風だったのでコードが煩雑にならないように捨てました
- LDA
- titleやevent_idの遷移をLDA → ユーザーごとに集計
- これはimportanceも低かった
- PageRank
Feature Selection
- Null Importancesで600個ぐらい削り、最終的には550個ぐらいの特徴量にしぼりました。
- Kaggle Days Tokyo の senkin-san slide のP18の式を利用
- gain_scoreがほんの少しだけマイナスのものまで使うとちょうどよかった
QWK threshold optimization
- kernelと同じものをやりました
- タイトルごとに最適化するのを何度もトライしましたが結局うまく行きませんでした。
Models
- 特徴量はすべて同じ(LightGBM以外は正規化している)で以下のモデルを作りました。
- LightGBMx3 (葉が多い/普通/少ない)
- パラメータはoptunaで最適化しました
- NN
- 特徴量作成で参考にしたカーネルと同じです
- 余談ですがBaseModelが結構キレイに作られていたので実装で参考にしました。
- Random Forest
- depth=6ぐらいでパラメータは適当でした
- LightGBMにやや劣るぐらいの精度が出て驚きました
- が、JackさんはLightGBMを捨ててXGBoostを選んだらしいのでそもそもLightGBMが微妙だった?
- Ridge
- LightGBMx3 (葉が多い/普通/少ない)
- LightGBM以外も意外と強かったので驚きました。
- すべてのモデルでSeed Averagingを行って、アンサンブルを行いました。
Ensemble
- StackingとWeightedAverageで迷いました。手元の実験ではStackingが強かったのですが、以下2つの理由で結局WeightedAverageにしました。(-0.002ぐらいのロスでした)
- publicLBの数字がWeightedAverageが強かった
- trainとprivateが乖離してるときに爆死するのが怖かった
- WeightedAverageのウェイトはoptunaで探索するようにしました
- Stackingは2段のつもりでした。
- LightGBMx3+NN+Ridge+RF → Ridge
- 4th solution見てると3段でやってるので驚きました(いつか試す)
- petfinderの解法に出てきたrank化したけど(多分)あんまり関係なかった
最終結果
- public: 17th (0.570) → private: 56th (0.551) (3500teams)
コンペを通しての感想
- Shake downして疲れた
- 一時はまぐれで5位まで順位を上げることが出来ました。
- 捨てサブだったので自分でもまぐれだとわかっていたものの、夢と希望が膨らまざるを得ませんでした。
- 最終的には1ページ目の外まで飛んでしまい、疲れました。
- 自分よりpublicLBを信じて疲れた
- コンペ開始直後はpublicLBは気にしないでおこうと心に誓っていたのですが、コンペ終了間近で判断に困ったときに、なにか心の拠り所が欲しくて結局見てしまいました。その結果、いくつか信念を曲げたことで-0.006程度のロスになってしまった。(結果論ですが)
- コンペ中盤の余裕のあるときにポリシーを明文化して貼っておく、とかしたほうが良いかもしれない。
- 振り回されて特徴量生成がおざなりになったりしたのも痛かったですし、何より、なんであんなに頑張ってた自分を信じてあげられなかったんだ、ととても悲しい気持ちになりました。
- QWKに非常に手こずって疲れた
- 様々な方法でQWKハック/安定化を試みたが大半は徒労に終わりました。
- ただ、oofをサンプリングして平均化したしきい値を求める、など結果的にみんなやってた手法を自分で見つけられてよかった。
- JackさんがQWKの直接の最適化をしていたらしく度肝を抜かれました。
- コードコンペに慣れたけど疲れた
- 今までのコンペはひたすらBQにSQL投げるマンだったのでpandas力上がって良かったです。
- コンペ終盤はFastSubmissinで回すことを覚え、PDCAのサイクルが格段に早くなりました。やっぱりGCPのデカいインスタンス最高。
- テストをちゃんと書いたので、いくつかのサブでミスが発見できて助かりました。
自分を信じられなかった人の末路
サブ履歴を見返した。pubに惑わされて手元のテスト結果や自分の信念を曲げたのが下記2点だった。これがなければ0.556+ぐらいだったか。金は無理だったかもだけど心の弱さが出たのでとても悔しい
— ML_Bear (@MLBear2) 2020年1月23日
・DataAugumentationを捨てた(-0.004)
・EnsembleにStackingではなくWeightedAverageを選択した (-0.002)
まとめ
感想が3つとも疲れたになってしまいましたw 各種トラブルを含む3週間チャレンジでとにかく疲れたのですが、まぁ楽しかったかなーと。
3月からウォルマートのコンペが始まるみたいなので、それまで色々勉強して準備して、また疲れる日々を過ごせれば嬉しいなと思います。
冷静に読んでみると、なにを言っているのか(ry な感想ですね笑。
Kaggle Days Tokyo オフラインコンペ参戦記
これはなに?
- Kaggle Days Tokyo 2日目に開催されたオフラインコンペの参加記録です。
- 参加88チーム中 25位(ソロ)と微妙な順位でしたが、これまでのkaggle参加の経験がとても活きて嬉しかったのと、コンペ後の懇親会が非常に楽しかったので、記録を書き留めておきます。
どんなコンペだった?
- NIKKEI電子版のサイト閲覧ログを元に、ユーザーの年齢を推定するというお題でした。
- 与えられたデータの種類は以下の2つでした。(情報はざっくりで書いてます)
- ユーザーの記事閲覧ログ
- 記事ID / user_id
- 読了率/閲覧時間
- 接続元情報(地域/法人IP等)
- 接続デバイス/OS/ブラウザ/通信
- 記事データ
- 記事ID
- カテゴリ/ジャンル/ラベル/キーワード
- タイトル/本文/文字数
- ユーザーの記事閲覧ログ
- ユーザー別に記事閲覧ログを集約して、そのデータをモデルに突っ込むというのが基本戦略になります。
- イベントログ+NLPで年齢推定という面白いお題でしたが、権利関係からか既にデータは削除されており、ちょっとだけ残念ではあります。
コード (jupyter notebook)
- Githubにあげておきました。
- データの内容は参加者以外に表示していいかどうか分からなかったので消してあります。予めご了承下さい。
- 後述するように
kiji_idを特徴量として使っていない点と、target encodingのやり方が怪しい点にはご注意下さい。 - こうしたほうがええんちゃう?みたいなのがあれば何なりとご指摘下さい。
1日の流れ (ざっくり)
| 時間 | 内容 | LB (Rank) |
|---|---|---|
| 10:30 | コンペ開始!とともにサイト&WIFI激重でデータが全然DLできなくて意外とヒマw | ー |
| 11:00 | pandas-profilingなどを使いつつデータを全体的に眺める。予想外にNLP要素が強そうでちょっと焦る。 | ー |
| 12:30 | GCPにインスタンス立上げる。ケチらずnot_preemptiveの32coresを選択。 | ー |
| 13:00 | 昼ごはん食べながらベースモデル作る。ちらし寿司が美味しくて結構たくさん食べて幸せ。 | ー |
| 13:30 | 毎度ながらtargetのカラム名を間違えつつ無事に初サブ | 12.88 (30位?) |
| 15:00 | データ前処理しつつカテゴリ変数系を target encoding | 12.55 |
| 15:30 | OS/browser系を真面目に処理して target encoding | 12.49 |
| 16:00 | 記事のメタデータ使いはじめる | ↑ |
| 16:30 | 記事のジャンルやラベルを target encodingで使ったらスコア爆伸びしてTOPまで0.3?差程度の9位に。 メタデータ軽く使うだけで前のサブから0.4ぐらい一気に上がったので、これワンチャンあるかな?と思って慢心する(爆) |
12.05 (9位) |
| 17:00 | ジャンルやラベルのユーザー別履歴をLDA (TalkingData1st的な) | 12.00 |
| 17:30 | MeCab Neologd のinstallに手こずってイライラする (諦めた) | ↑ |
| 17:30 | キーワードやタイトルをMecabで分かち書き → ユーザーごとに履歴取って並べてLDA | 11.95 (15位前後?) |
| 18:00 | 記事本文の処理を書くが重くて処理が終わらなさそうな感じが出てきてあたふたする | ↑ |
| 18:30 | そのまま無事終了 (ノ∀`)アチャー |
pub: 26位 priv: 25位 |
振り返り: 良かったこと編
事前準備がきちんと活きた
- 普段の業務ではBigQueryでSQL芸人をしているので、pandas処理にあまり自信がありません。
- ただ、IEEEコンペでチームメンバーの圧倒的なデータ処理能力を見せつけられていたため、SQLだと短時間勝負においてどうしても手数が劣るということはわかっていました。
- なので、こういうの使うかな?という処理は一通り事前に書いていきました。(EloコンペでKernelコピペしてたものがあるのを思い出したので、引っ張り出して復習しつつ書きました。)
kaggleで得た知見が活きた
- 特徴量選択(ほぼ)しない
- 普段のkaggleコンペだと10-30個づつぐらいモデルに足してスコアが上がったら採択、ということをしています。
- が、時間がかかることと、最終的なスコアの影響が大きくないような印象があるので、今回は作った特徴量を一部を除きひたすら足していきました。
- parameter tuning(ほぼ)しない
- optunaでパラメータチューニングを軽く行いましたが、手で決めたものと大して変わらなかったのでこだわりませんでした。
- 特徴量をひたすら作るほうが時間効率が良いことが分かっていたので、迷いなく判断できてよかった。
- 比較的トリッキーな特徴量の活用
- トピックモデルの考えを応用して閲覧ログをLDAで分解する的なやつ
- 並列処理計算の活用
- コア数で殴る処理のコードを書き溜めていたので役に立ちました
- seed averaging を忘れずにやった
- タスクによってめっちゃ効くものもあると記憶していました (分子コンペで誰かが言ってた)
- 軽微なスコア向上でしたが、やらないよりは全然良かった。
振り返り: 良くなかったこと編
try everything 精神の欠如
- 時間的制約があったとはいえ、簡単にできる範囲の中でさえ try everything しなかったのは痛恨の極みです。
- 例
kiji_idを確たる理由もなく何故かtarget encodingの対象から外した- どこかで「1人にしか読まれていない記事たくさんありますねー」という言及を見ていた。
- その言及が何故か頭に残っており「まぁなんか危なそうだし入れなくていいや」みたいな雑な理由で外してしまった。
- これが圧倒的なMagicFeatureだったと懇親会で何人かから聞いたので、
- 試しにLate submission用にコードを2行変更してtarget encodingの対象に入れた。すると、大幅なスコア上昇がみられた。悔しい。
private 11.49199 (25位) -> 11.41579 (11位)
- target encodingのしきい値を軽く調整すれば、さらに上昇して余裕でTOP10に入れた…。死ぬほど悔しい…。
private 11.49199 (25位) -> 11.30513 (6位)
- 試しにLate submission用にコードを2行変更してtarget encodingの対象に入れた。すると、大幅なスコア上昇がみられた。悔しい。
- senkin-sanのカーネルと混ぜるという発想がでてこなかった。適当にaveragingするだけでそこそこの順位上昇を得られた。
pribate 11.49199 (25位) -> 11.45726(18位)
- NaNカウントとかしてない
- 過去のコンペであまり効いたことがなかった
- 今回は効くとか効かないとか (AdversarialValidationに悪影響があるという人もいた)
チームを組まなかった
- 記事のメタデータ軽く入れるだけで9位になったときに、これソロでもワンチャンあるんじゃね?と思ってしまった。(今思うとめちゃ恥ずかしい)
- 終盤は作業で手一杯になってチーム組んでくれませんかーってお願いしにいく気力がわきませんでした…。
これ勉強しなきゃな、と思ってたところで躓いた。
- 前々から、自分の target encoding のやり方はやや亜流(or コンサバ)だと認識はしていました。
- 基本的にN件以上データある人だけ対象にしてtarget encodingを計算しています(N=500とか1000とか)
- いつか勉強しようと思っていたが、結局勉強せず、亜流のやり方でやってしまっていました。
- 懇親会で色々聞いていると、良い成績を残している人は当たり前のようにきちんと工夫されていて、自分との大きな差を感じました。
- kaggle本に載っているようなFold内でFold切って計算する方法
- weight of evidence (smoothing) の利用
- Leave one out で計算して、aggregation時に重み付けをきちんと行う
- 同様に、多くはないですがNNも普通に組んでる方もいらっしゃいました
- もっと上位の極限の勝負になったら絶対に競り負けるなと思いました
戦略性の欠如
- これはあとづけかも
- aggregation系の特徴量は senkin-san がめっちゃ上げてくれてたので、ソロでやるなら時間の多くをNLP処理に振り切って、senkin-san のカーネルから特徴量を拝借する、とかでも良かったかも知れないです。
参考になったソリューション
時間が足りなくてできなかったものがメイン。もっと色々聞いたはずなのに2次会のワインともに脳みそから流れ出てしまっている…。
- 閲覧ログデータごとに年齢推計→ユーザー別に集計し特徴量に
- ユーザーがみた記事ID履歴からword2vec→閲覧記事vectorをユーザーごとに集計
- 記事本文からword2vecモデルをスクラッチ学習 → タイトルや記事本文の解析に利用
- 記事タイトルのTF-IDFをSVDで次元削減
- 理解しきれなかったけど雰囲気はつかめたもの
- 閲覧記事IDの羅列をNNに突っ込んでembedding(?)
楽しかったこと
- めっちゃ知り合い増えた
- 自分は雑談能力があまり高くなく人見知りもするので、立食パーティーには相当の苦手意識があります苦笑。
- コンペやったあとだと、どんな工夫されましたか?とか比較的簡単に打ち解けられました。
- 結果として、(当社比)たくさんの方とお話できて楽しかった。立食パーティー楽しいと思ったの人生で初かもしれないです笑。
- コンペタスクが純粋に面白かった
- 比較的焦ってたけど、へぇ〜こんなデータも効くんだー、とか、やっぱこれ効くよねー、とか思いながらコンペできてたので、タスクは相当面白かったと思います。
まとめ
- オフラインコンペ楽しかったから今後も機会作って参加したいと思います。一緒にコンペで戦って(&自分をボコって)くださった皆様ありがとうございました。
- この記事ではオフラインコンペにしか触れませんでしたが、1日目のセッションも得るものが大変多かったです。
- このような機会を頂いたKaggle Days Tokyoの運営の方々には多大なる感謝です。(次に激アツメールきたら貢献できれば嬉しい)